
此文章仅供新问云图工作室内部人员交流学习使用。
此文档旨在便于内部组员学习如何部署并且使用Hadoop及其相关组件,主要用于演示展示,并非生产用途编辑版本
06月13日第一版 编辑人:LRAltas
实验环境
平台:ESXI 8.0
系统:CentOS-Stream 9所需软件包
mysql-5.7.25-linux-glibc2.12-x86_64.tar.gz
sqoop-1.4.7.bin_hadoop-2.6.0.tar.gz
jdk-8u201-linux-x64.tar.gz
mysql-connector-java-5.1.47-bin.jar
PC上需要jdk-8u181-windows-x64.exe
前置条件
由于是测试环境,所以请先关闭操作机器上的防火墙,如果有SElinux也请关闭SElinux,并且将当前主机上的IP设置成Static,并且配置ssh免密
在CentOS-Stream 9-10上面,网络设置有NetWorkManager来接管,如果是非图形化界面,可以使用nmcli来进行网络配置更改
下面是一段实示例
在进行编辑之前请先查看你的网卡叫什么
ip add
#会输出类似于以下内容
[root@hadoop01 ~]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:3d:24:fc brd ff:ff:ff:ff:ff:ff
altname enp3s0
inet 192.168.77.146/24 brd 192.168.77.255 scope global dynamic noprefixroute ens160
valid_lft 1547sec preferred_lft 1547sec
inet6 fe80::20c:29ff:fe3d:24fc/64 scope link noprefixroute
valid_lft forever preferred_lft forever
#在我给出的示例中ens168就是我们当前使用的网卡,双网卡选取任意一个即可,注意,每个虚拟机上的一般是ens,实际物理机上不一定叫这个。 nmcli conn mod ensxx ipv4.address 192.168.77.146/24 ipv4.gateway 192.168.77.2 ipv4.dns 8.8.8.8 ipv4.method manual
#配置完成之后你应该刷新这个网卡以更新配置
nmcli conn down ens160
nmcli conn up ens160
#注意:VMware Workstation的虚拟NAT网卡网关一般是xxx.xxx.xxx.2一切准备就绪后我们将软件包发送至虚拟机
检查所需的文件是否齐全以及大小是否正常

准备好了之后就可与开始安装了
JDK与Hadoop的安装
由于Hadoop基于Java开发,Hadoop的核心框架(如HDFS、MapReduce、YARN等)是用Java语言编写的,因此运行Hadoop必须依赖Java环境(JDK或JRE)。JDK提供了Hadoop运行时所需的Java虚拟机(JVM)、类库和工具,安装Hadoop前必须安装JDK,且需配置JAVA_HOME环境变量指向JDK路径。
Hadoop的启动脚本(如start-dfs.sh、start-yarn.sh)会检查Java环境,若未正确配置JDK,Hadoop将无法运行。
注意: Hadoop需要JDK(而不仅是JRE),因为部分工具(如javac)在编译或调试时可能被用到。
由于CentOS本身就自带的有JDK,所以我们要首先检查自身JDK环境
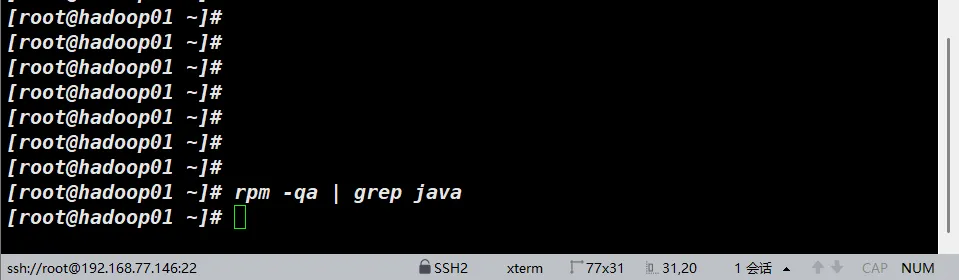
我是CentOS-Stream 9,标准安装,目前没有JDK
我们先创建给JDK的文件夹,你可以按照接下来给出的示例来,也可以自己设置。
注意:Ubuntu上对我们接下来的路径,如果没有root权限可能创建比较麻烦,而且做之前必须要提前备份好环境变量文件
安装JDK
创建JDK文件夹
mkdir /usr/local/jdk解压我们的文件到指定文件夹
tar -zxvf /root/hadoop_file/jdk-8u201-linux-x64.tar.gz -C /usr/local/jdk编辑环境变量使jdk生效
vim /etc/profile
#添加以下内容
JAVA_HOME=/usr/local/jdk/jdk1.8.0_201
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
CLASSPATH=.:JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib
export JAVA_HOME PATH CLASSPATH
#保存退出后
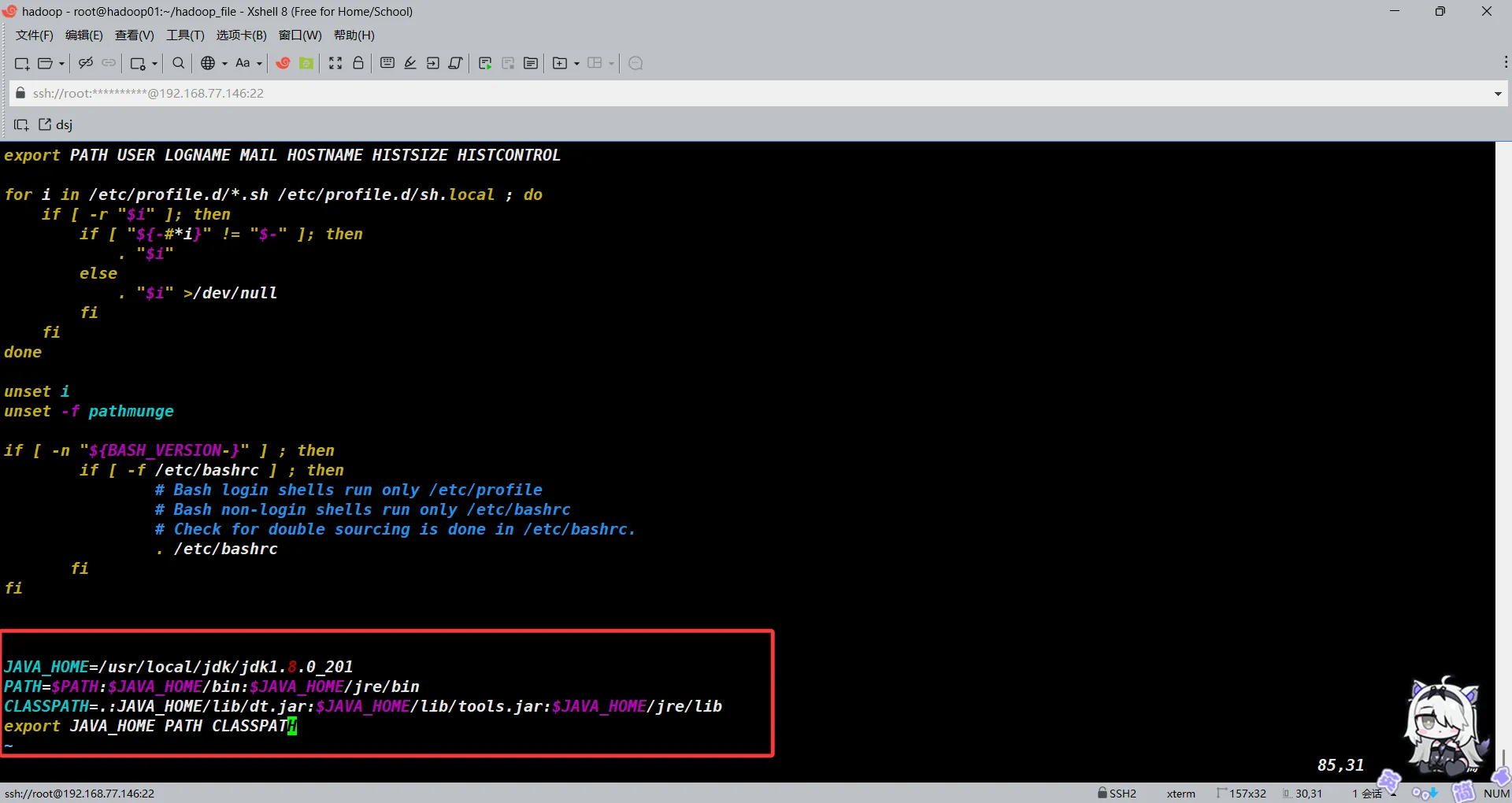
之后加载profile文件并验证
source /etc/profile
java -version
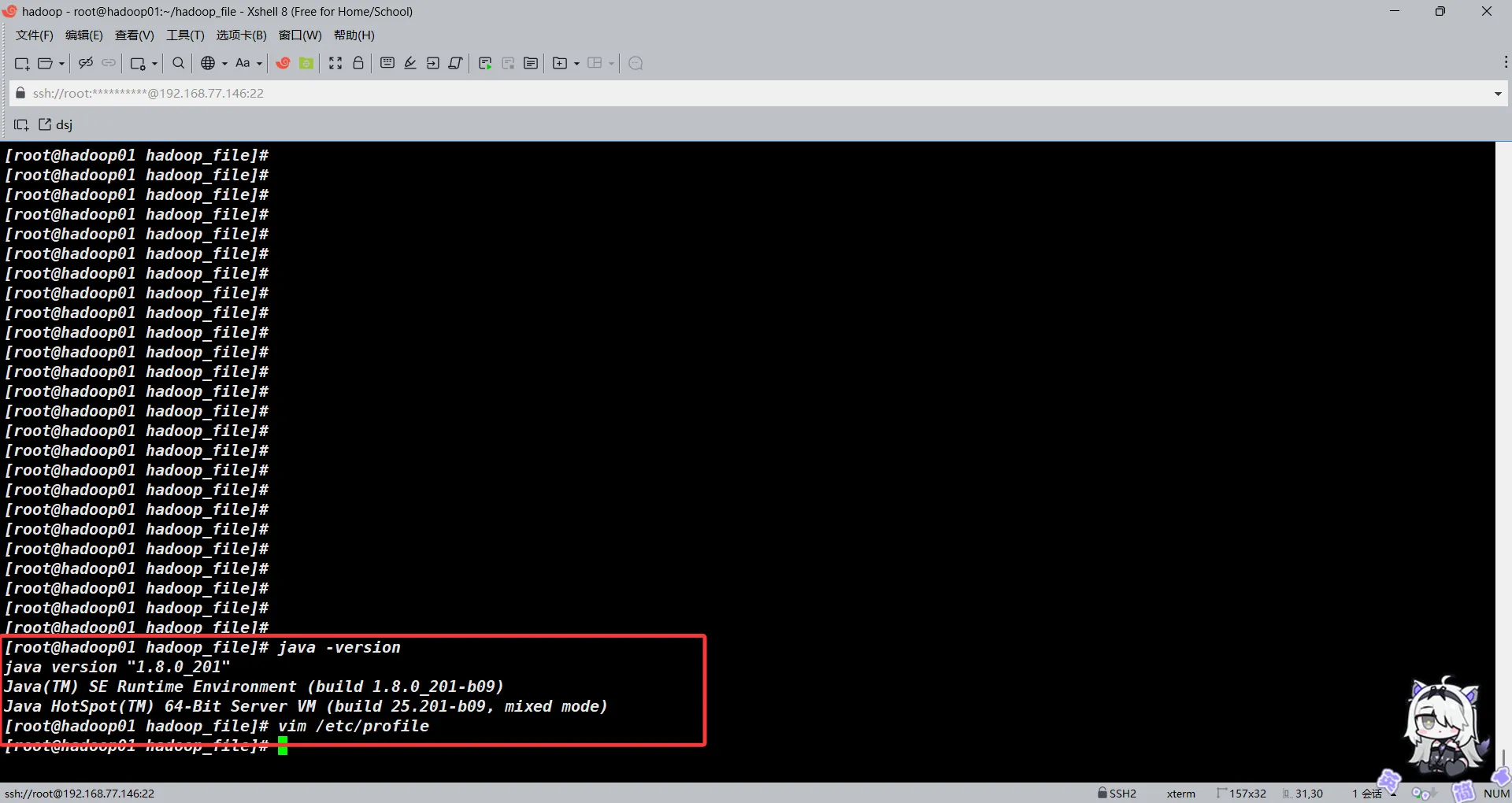
验证无误后开始安装并配置Hadoop
安装Hadoop
注意:此处我们所使用的Hadoop版本为2.7.7
创建Hadoop的文件夹并解压我们编译过hadoop的压缩包到指定位置
hadoop version
#创建Hadoop文件夹
mkdir /usr/local/hadoop
#解压hadoop文件
tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local/hadoop/
#备份环境变量
cp /etc/profile /etc/profile.bak
vim /etc/profile
#添加以下内容
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH
#保存退出重新加载环境变量
source /etc/profile键入hadoop version以查看hadoop是否安装成功
hadoop version
#如有类似于以下内容的部分输出即为成功
Hadoop 2.7.7
Subversion Unknown -r c1aad84bd27cd79c3d1a7dd58202a8c3ee1ed3ac
Compiled by stevel on 2018-07-18T22:47Z
Compiled with protoc 2.5.0
From source with checksum 792e15d20b12c74bd6f19a1fb886490
This command was run using /usr/local/hadoop/hadoop-2.7.7/share/hadoop/common/hadoop-common-2.7.7.jar配置Hadoop
此处我们要编辑的文件有如下几个文件
hadoop-env.sh
我们编辑该文件,取消掉其中的关于JAVA_HOME的注释部分
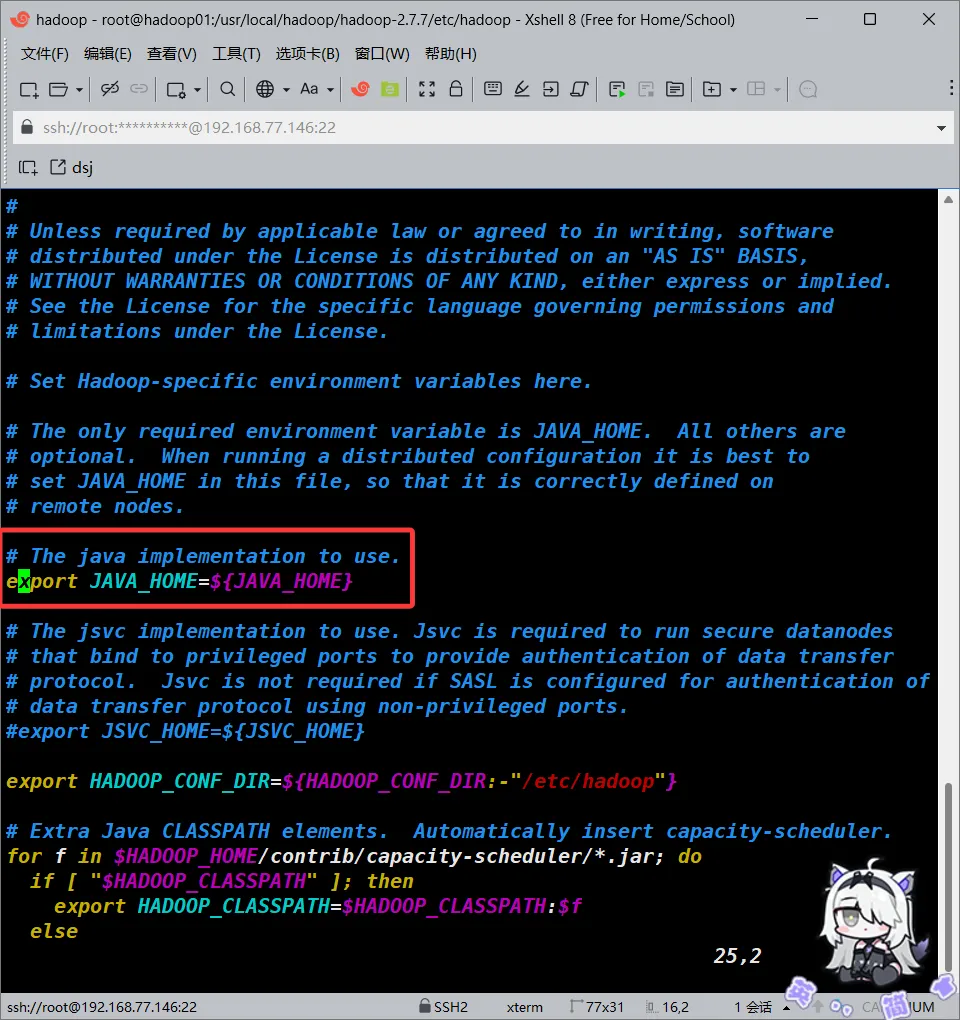
我的是这样的,本身没有背注释掉。你的这段可能是被注释掉的,如果是被注释掉的,你就将其取消注释即可。
core-site.xml
编辑该文件并添加对应内容
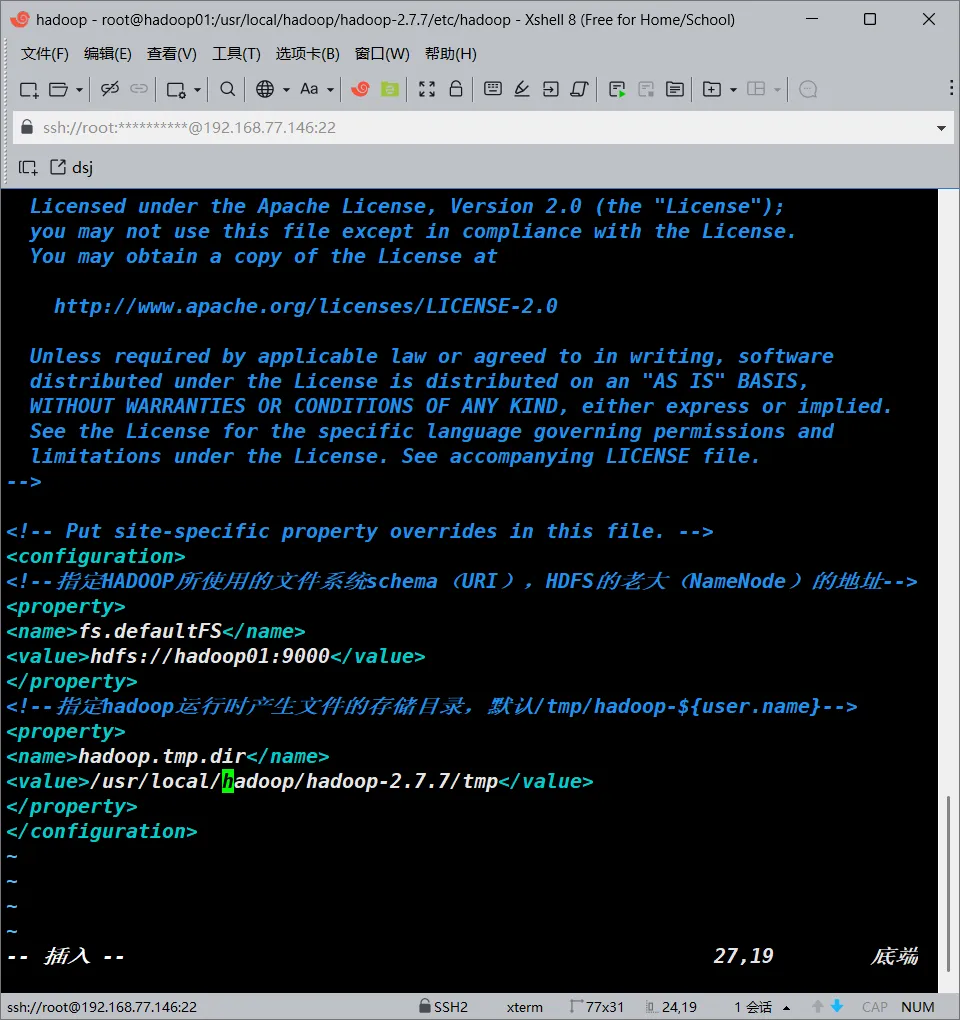
vim /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml
#添加以下内容
<configuration>
<!--指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!--指定hadoop运行时产生文件的存储目录,默认/tmp/hadoop-${user.name}-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.7.7/tmp</value>
</property>
</configuration>
#添加完成之后保存退出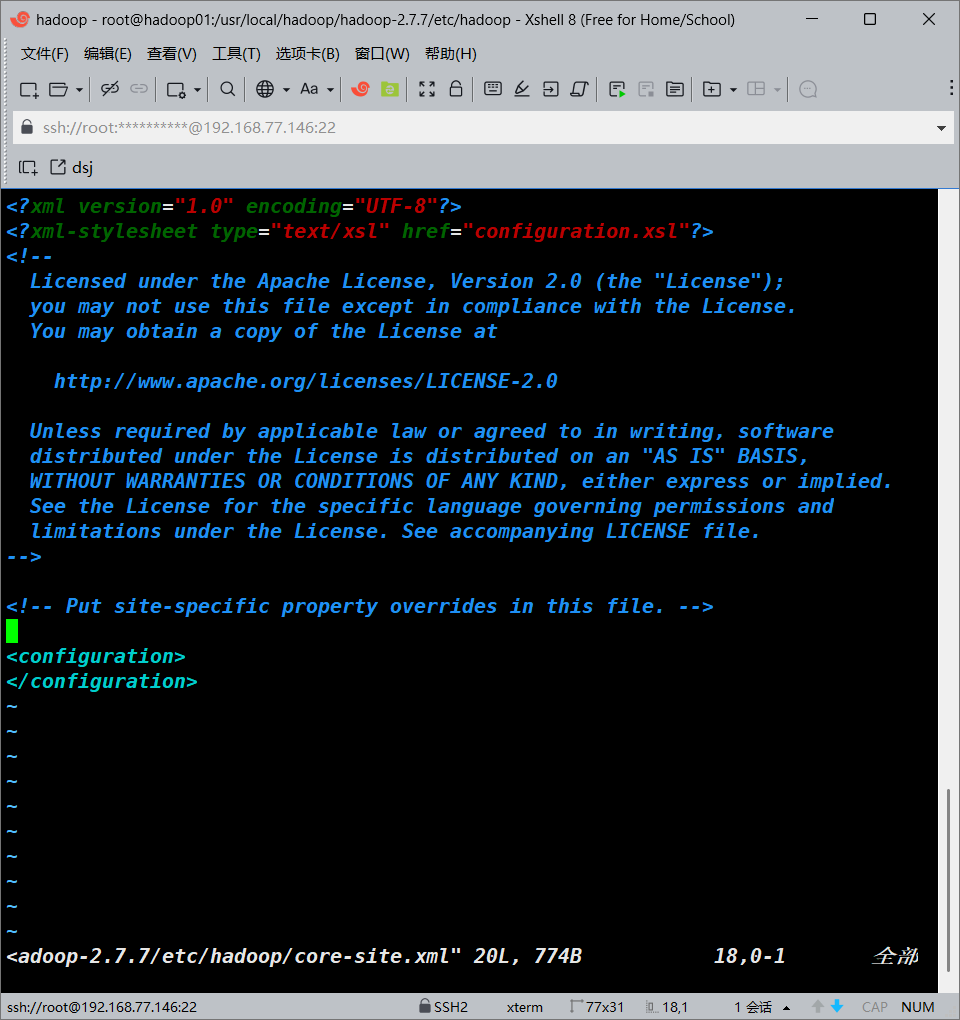
hdfs-site.xml
编辑并添加以下内容
vim /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
#编辑并添加以下内容
<configuration>
<!--指定HDFS副本的数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>mapred-site.xml
编辑并添加以下内容
由于源文件官方给的是个模板,所以我们要复制一份出来单独编辑
cp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/mapred-site.xml
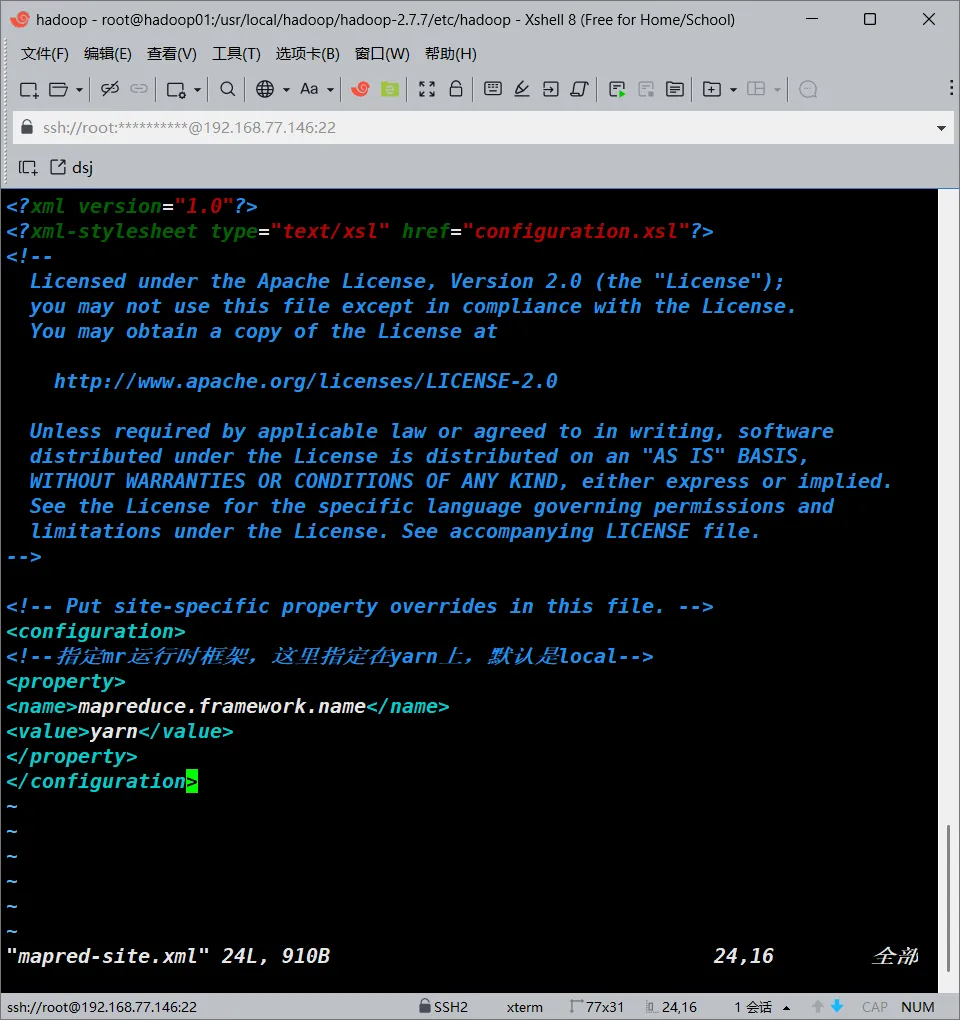
vim /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/mapred-site.xml
#编辑该文件并添加如下内容
<configuration>
<!--指定mr运行时框架,这里指定在yarn上,默认是local-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.yml
编辑并添加以下内容
#编辑并配置该文件
vim /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/yarn-site.yml
#添加以下内容
<!--指定YARN的老大(ResourceManager)的地址-->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:8088</value>
</property>
</configuration>
启动并验证Hadoop是否正常
#在环境变量全部配置好了的情况下,可以直接启动
#注意,这个直接启动在spark存在的情况下,不太行,因为spark的启动文件也是这个,到时候建议,分批次启动
#初始化namenode
hdfs namenode -format
start-all.sh
#如果正常应该会出现以下内容
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [hadoop01]
hadoop01: Warning: your password will expire in 0 days.
hadoop01: starting namenode, logging to /usr/local/hadoop/hadoop-2.7.7/logs/hadoop-root-namenode-hadoop01.out
localhost: Warning: your password will expire in 0 days.
localhost: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.7/logs/hadoop-root-datanode-hadoop01.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: Warning: your password will expire in 0 days.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-hadoop01.out
starting yarn daemons
resourcemanager running as process 2411. Stop it first.
localhost: Warning: your password will expire in 0 days.
localhost: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.7.7/logs/yarn-root-nodemanager-hadoop01.out
然后浏览器打开HADOOP01_IP:50070
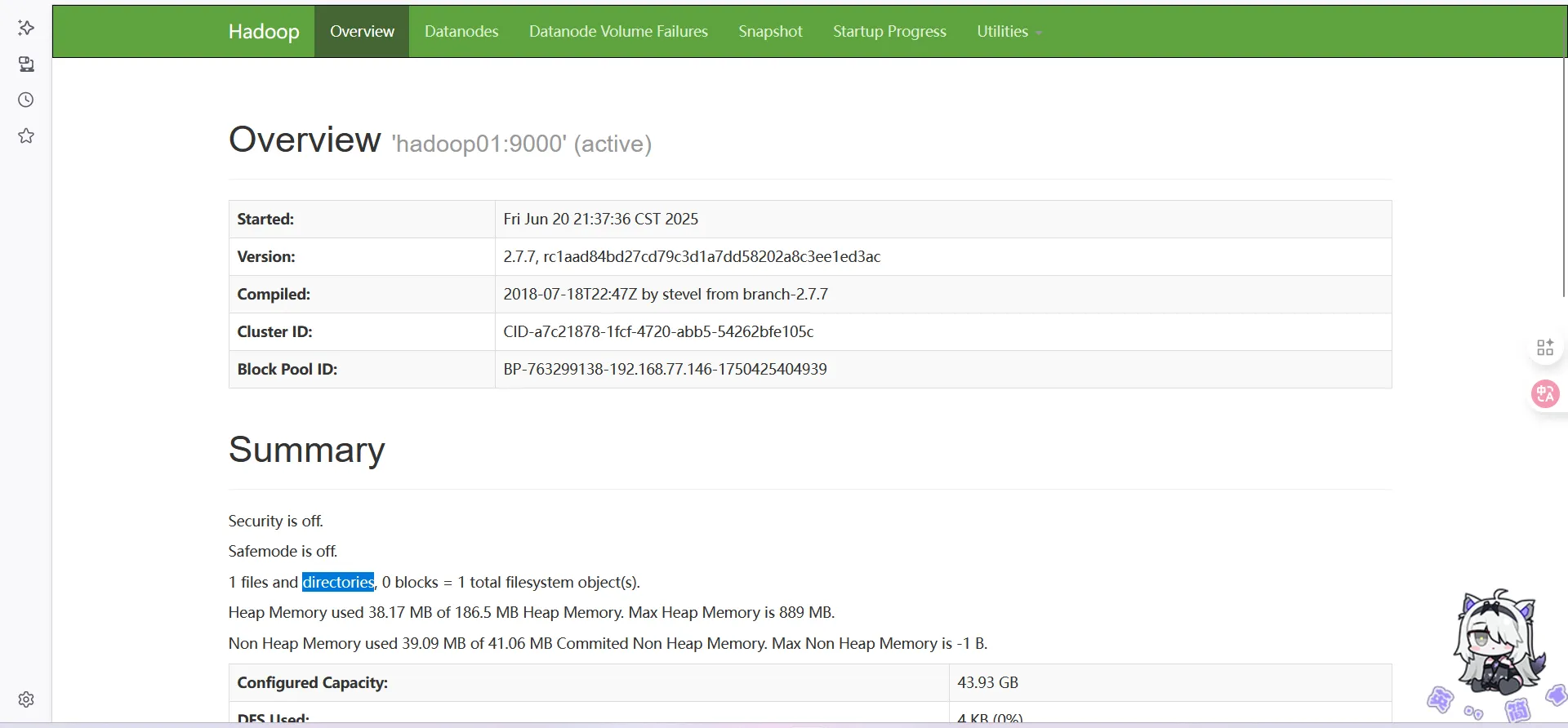
请注意此块是否为全0
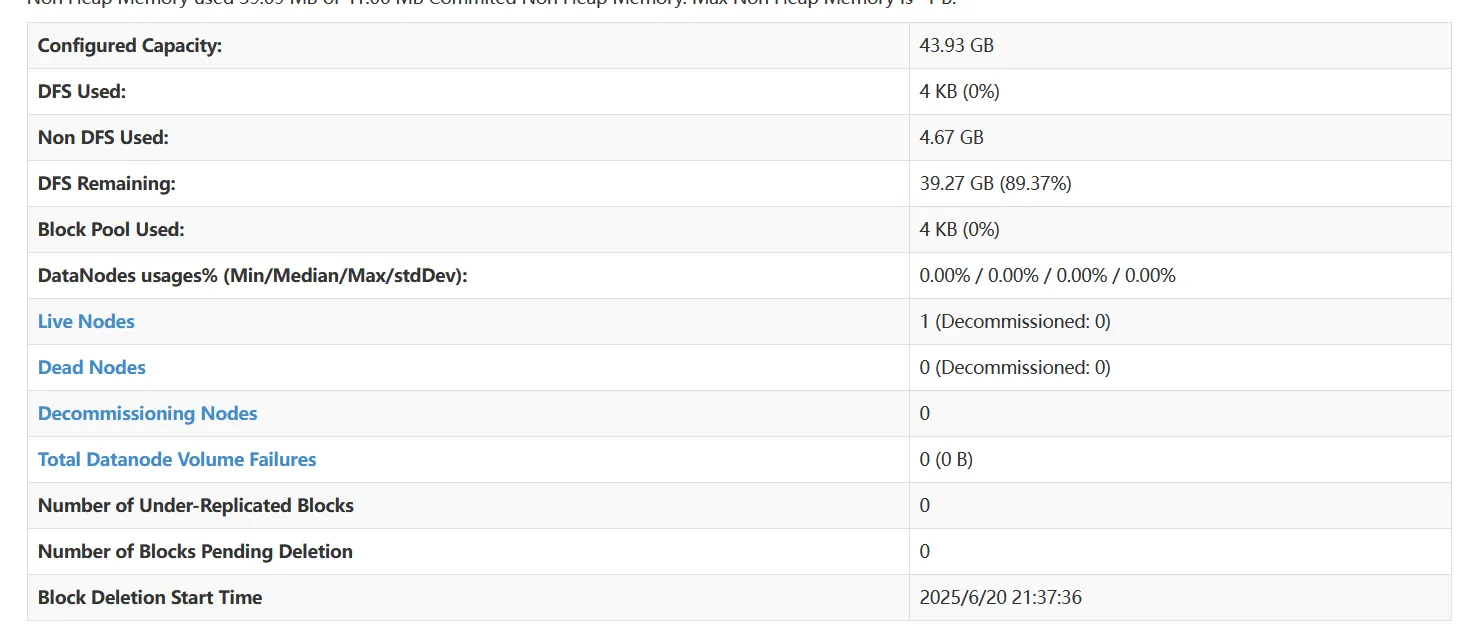
如果是全0,那么你应该去检查你的元数据是否出现了问题
如果没问题,那么基本的Hadoop本体,就是安装完成了。
关于与zookeeper以及相关高可用可以查看关于工作区大数据知识库里的关于Hadoop集群的部署文档。
Hbase的部署
事前准备
首先先给Hbase创建一个文件夹
mkdir /usr/local/hbase解压Hbase到指定文件夹
tar -zxvf hbase-1.2.10-bin.tar.gz -C /usr/local/hbase配置Hbase
hbase-env.sh
编辑hbase-env.sh
由于Hbase运行需要JDK环境,所以我们要配置其Hbase的JAVA_HOME路径
编辑并添加以下内容
#文件位于/usr/local/hbase/hbase-1.2.10/conf下
vim /usr/local/hbase/hbase-1.2.10/conf/hbase-env.sh
#添加以下内容
export /usr/local/jdk/jdk1.8.0_201
#添加好了后保存退出hbase-site.xml
编辑hbase-site.xml并添加以下内容
#创建一个文件夹用于保存hbase数据存储
mkdir /usr/local/hbase/data
#编辑hbase-site.xml文件
vim /usr/local/hbase/hbase-1.2.10/conf/hbase-site.xml
#添加以下内容
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/hbase/data</value>
<description>The directory shared by RegionServers.</description>
</property>
</configuration>
#添加好了后保存退出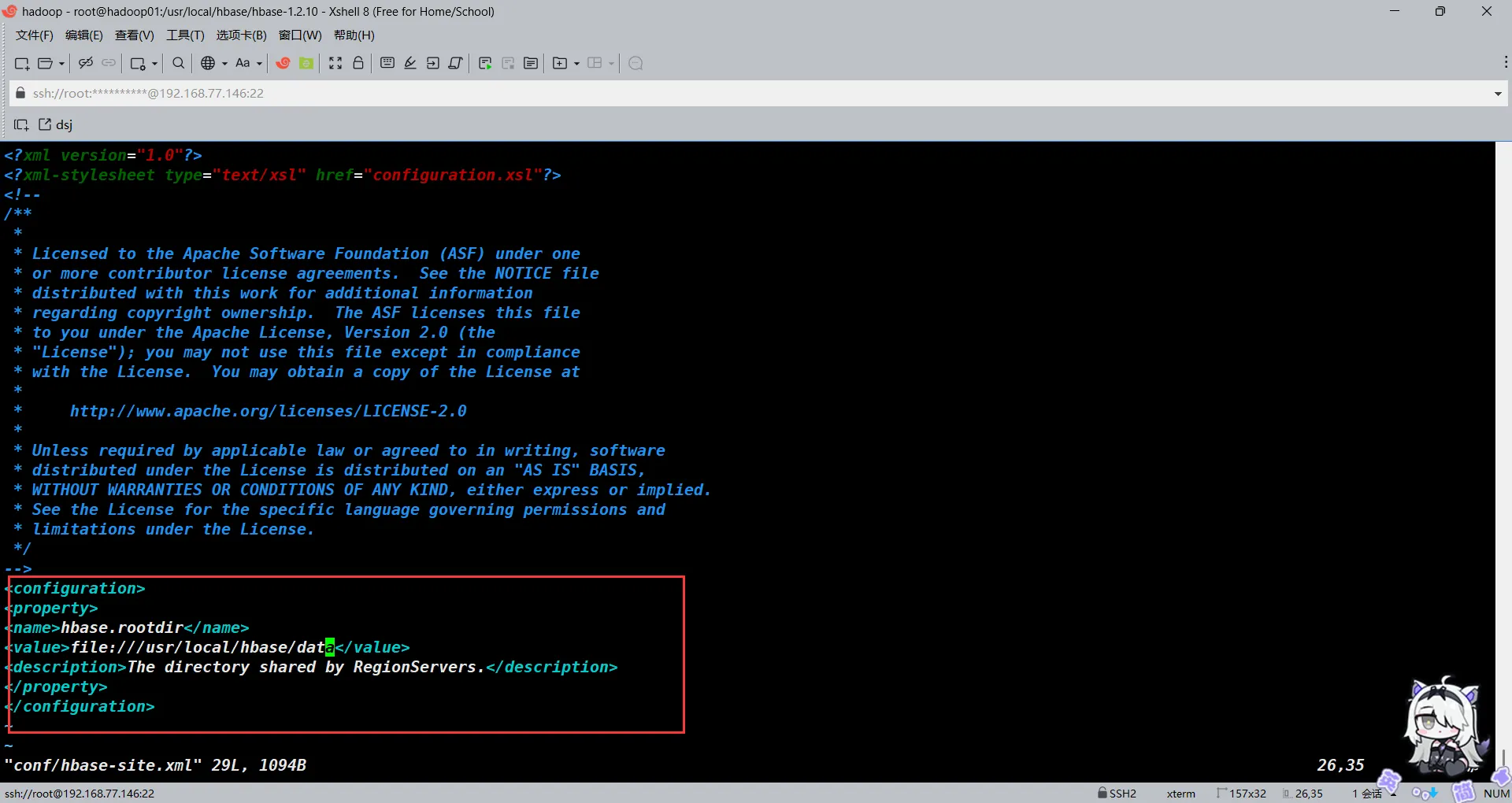
配置环境变量
vim /etc/profile
#添加以下内容
HBASE_HOME=/usr/local/hbase/hbase-1.2.10
PATH=$PATH:$HBASE_HOME/bin
export HBASE_HOME PATH
#好了之后保存退出
#重新source一下环境变量使配置生效
source /etc/profile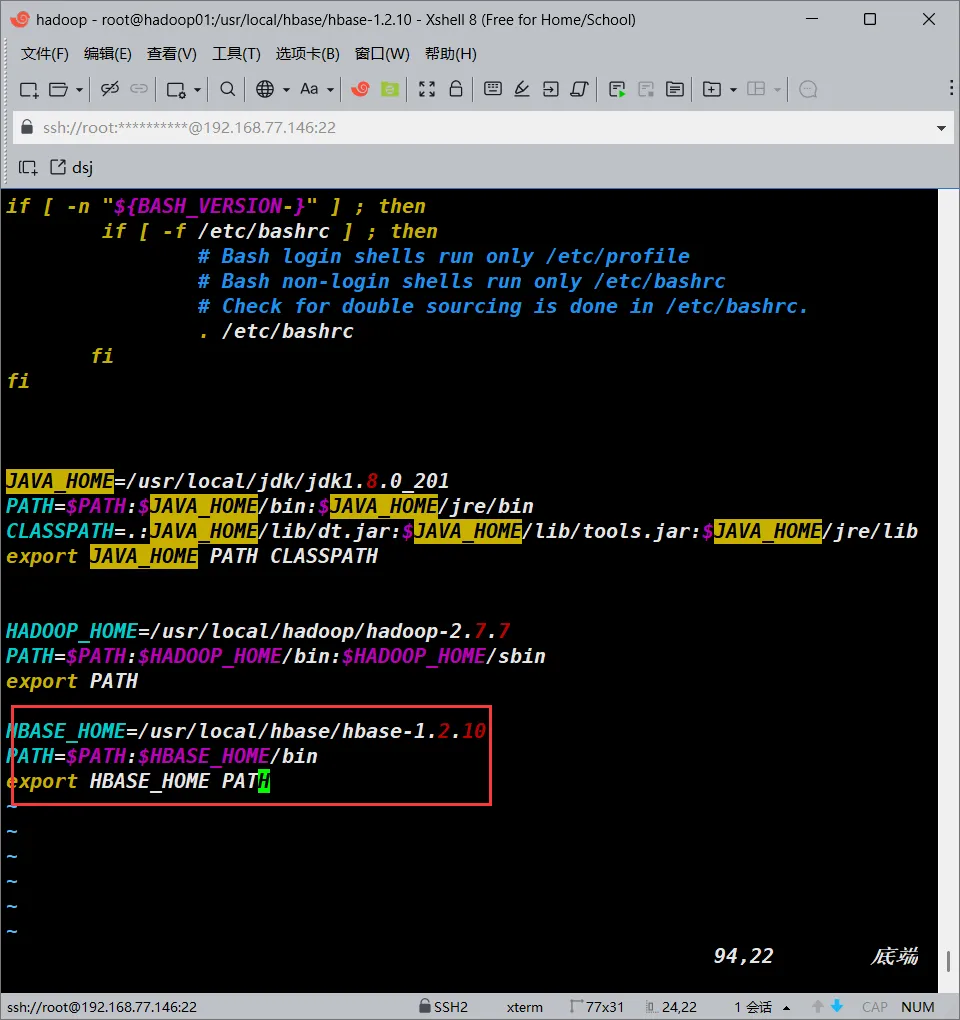
验证安装
终端键入hbase version
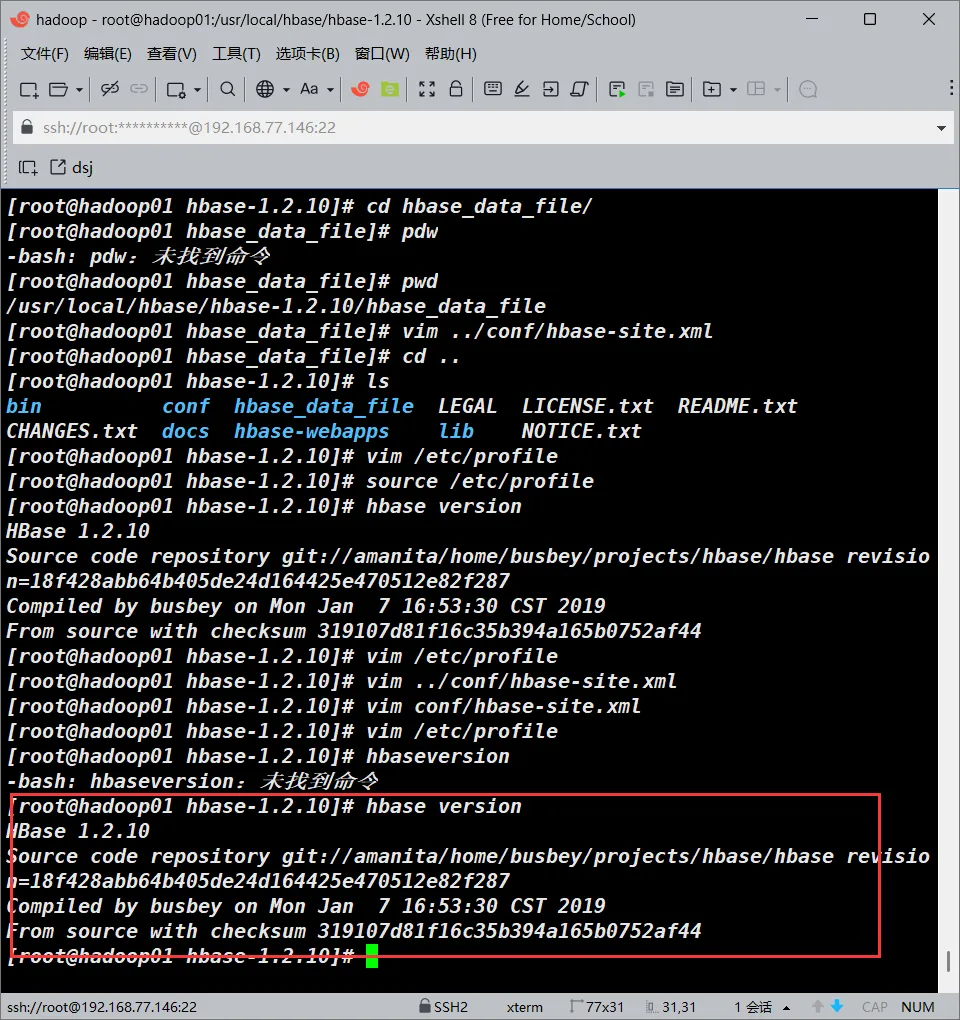
hbase version
#如果正常安装一般会有以下输出
HBase 1.2.10
Source code repository git://amanita/home/busbey/projects/hbase/hbase revision=18f428abb64b405de24d164425e470512e82f287
Compiled by busbey on Mon Jan 7 16:53:30 CST 2019
From source with checksum 319107d81f16c35b394a165b0752af44
启动hbase
strat-hbase.shjps查看一下进程
jps
#如果出现了HMaster进程,并且不会消失可以进行下一步
3072 DataNode
2913 NameNode
3258 SecondaryNameNode
2411 ResourceManager
3499 NodeManager
5502 HMaster
5775 Jps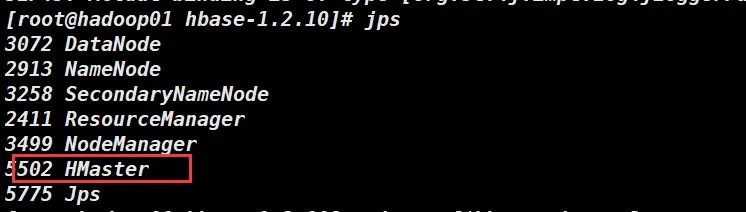
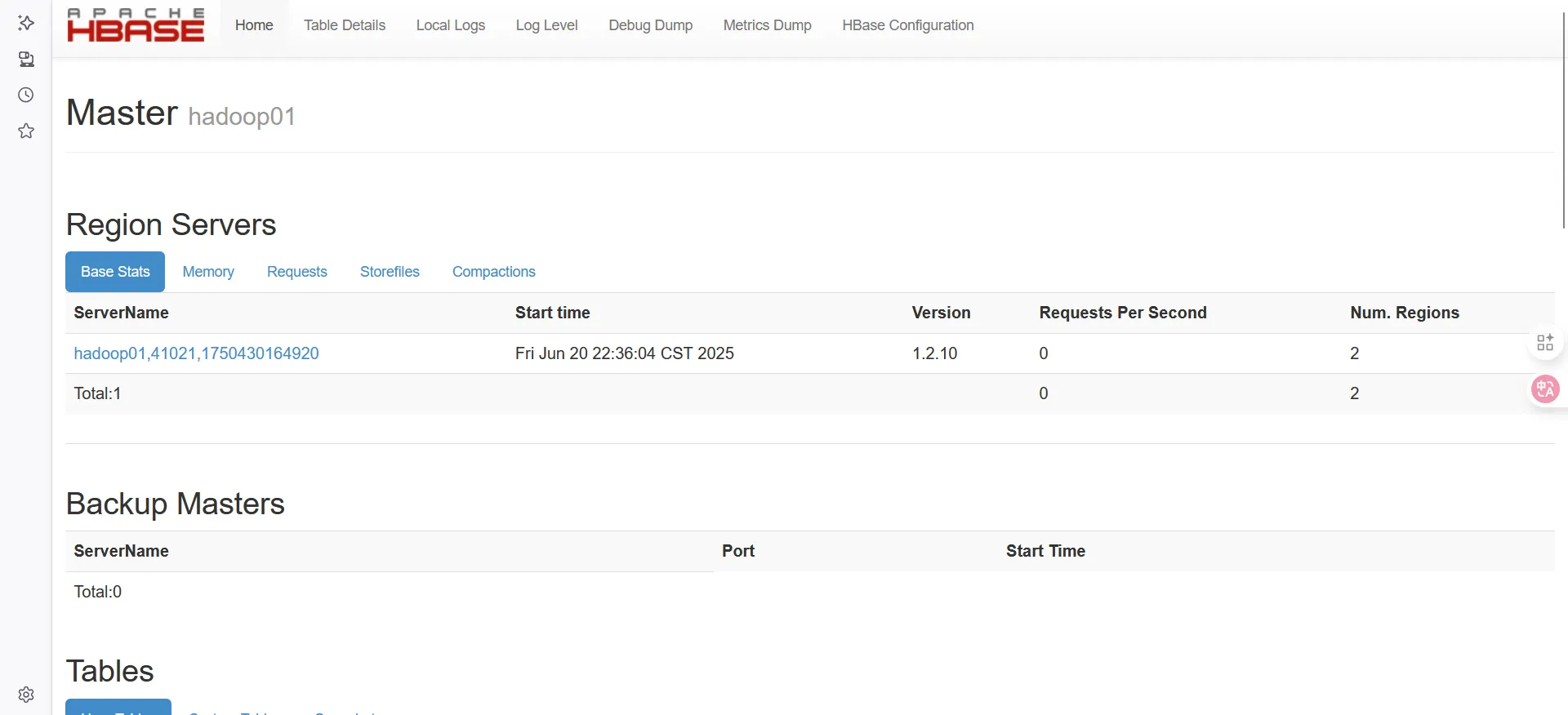
浏览器打开HADOOP_IP:16010
出现以下界面即为成功
Sqoop与mysql部署
事前准备
创建sqoop的文件夹并解压sqoop到指定位置
mkdir /usr/local/sqoop && tar -zxvf /root/hadoop_file/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/sqoop编辑并配置sqoop
sqoop-env.sh
#源文件是sqoop-env-template.sh,一个模板文件,你要将其复制一份出来
cp /usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/conf/sqoop-env-template.sh /usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/conf/sqoop-env.sh 配置sqoop-env.sh
vim /usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/conf/sqoop-env.sh
#添加以下内容
export HADOOP_COMMON_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-2.7.7
#完成后保存退出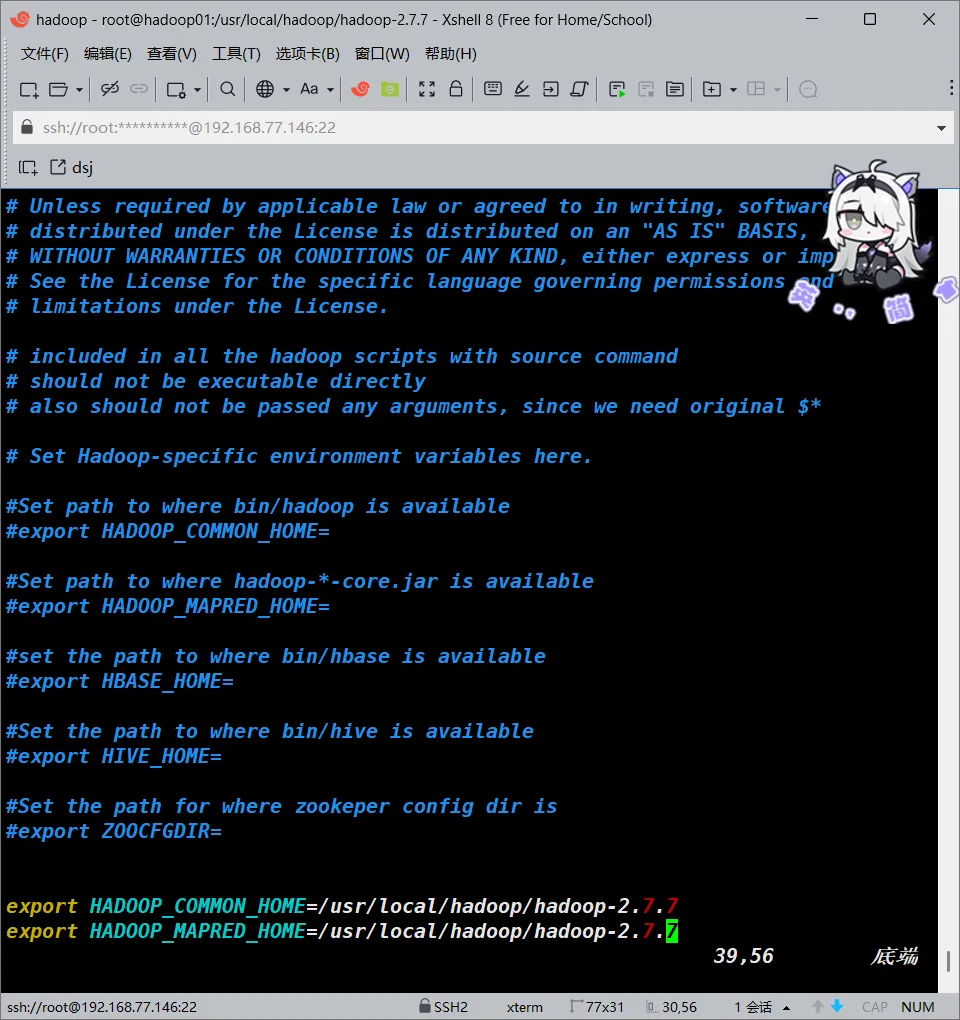
配置环境变量
#配置环境变量
vim /etc/profile
#添加以下内容
SQOOP_HOME=/usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0
PATH=$PATH:$SQOOP_HOME/bin
export SQOOP_HOME PATH
#好了之后保存退出
#重新加载环境变量
source /etc/profile验证安装
sqoop version
#验证安装
Warning: /usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
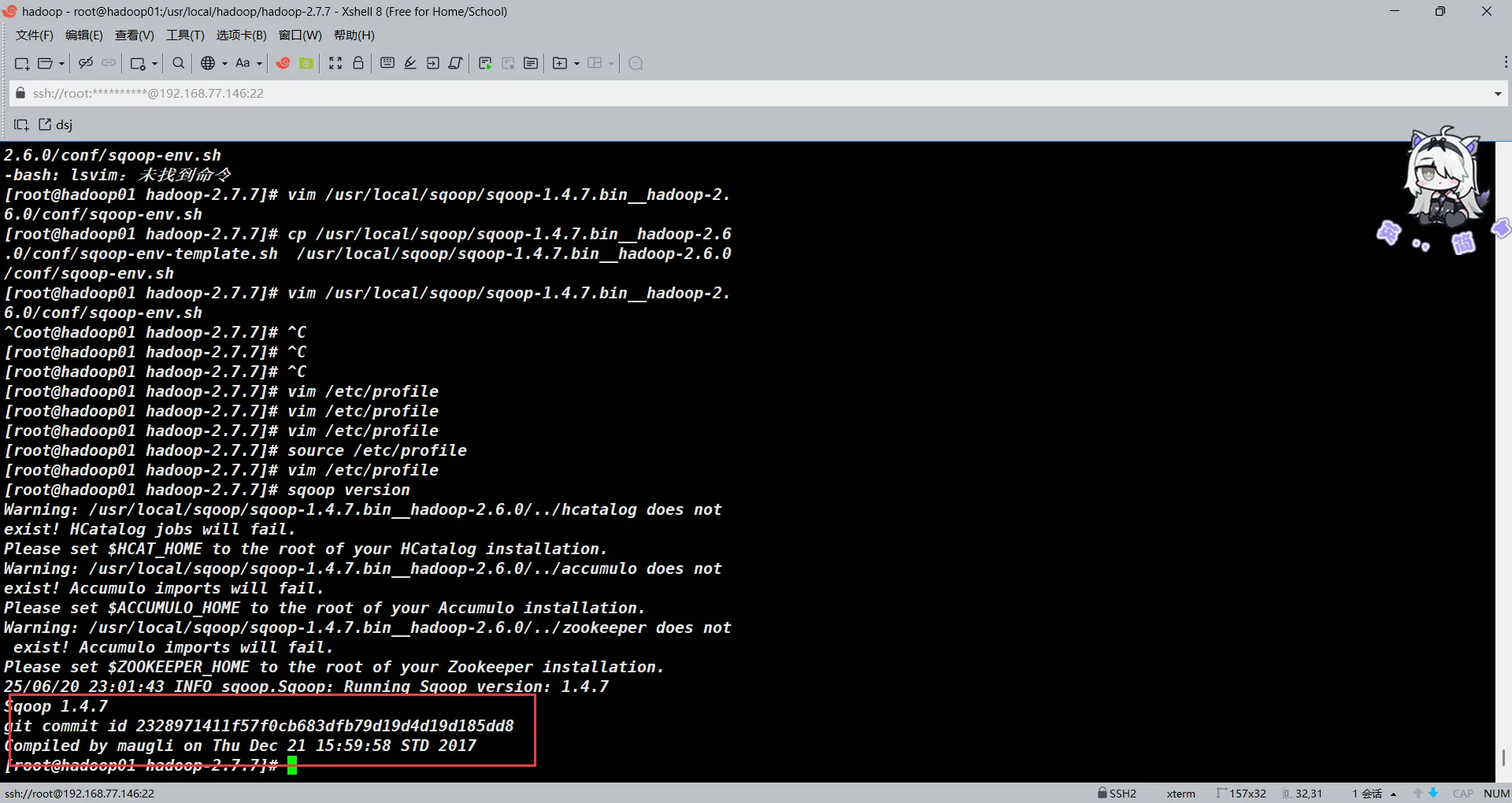
25/06/20 23:01:43 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Sqoop 1.4.7
git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8
Compiled by maugli on Thu Dec 21 15:59:58 STD 2017
由于我们没有安装部署HCAT,ACCUMULO以及ZOOKEEPER所以找不到对应的HOME路径是正常的,只要sqoop的版本能正常输出即可
至此,我们的sqoop暂且还不能用,因为sqoop本身是没有mysql的驱动包的,我们需要对应的驱动包
此处我们使用的是mysql-connector-java-5.1.47-bin.jar,这个文件上述软件清单里面给了tar包的下载链接,下载后解压,里面就有这个文件
在hadoop_file文件夹解压即可
cd /root/hadoop_file && tar -zxvf /root/hadoop_file/mysql-connector-java-5.1.47.tar.gz 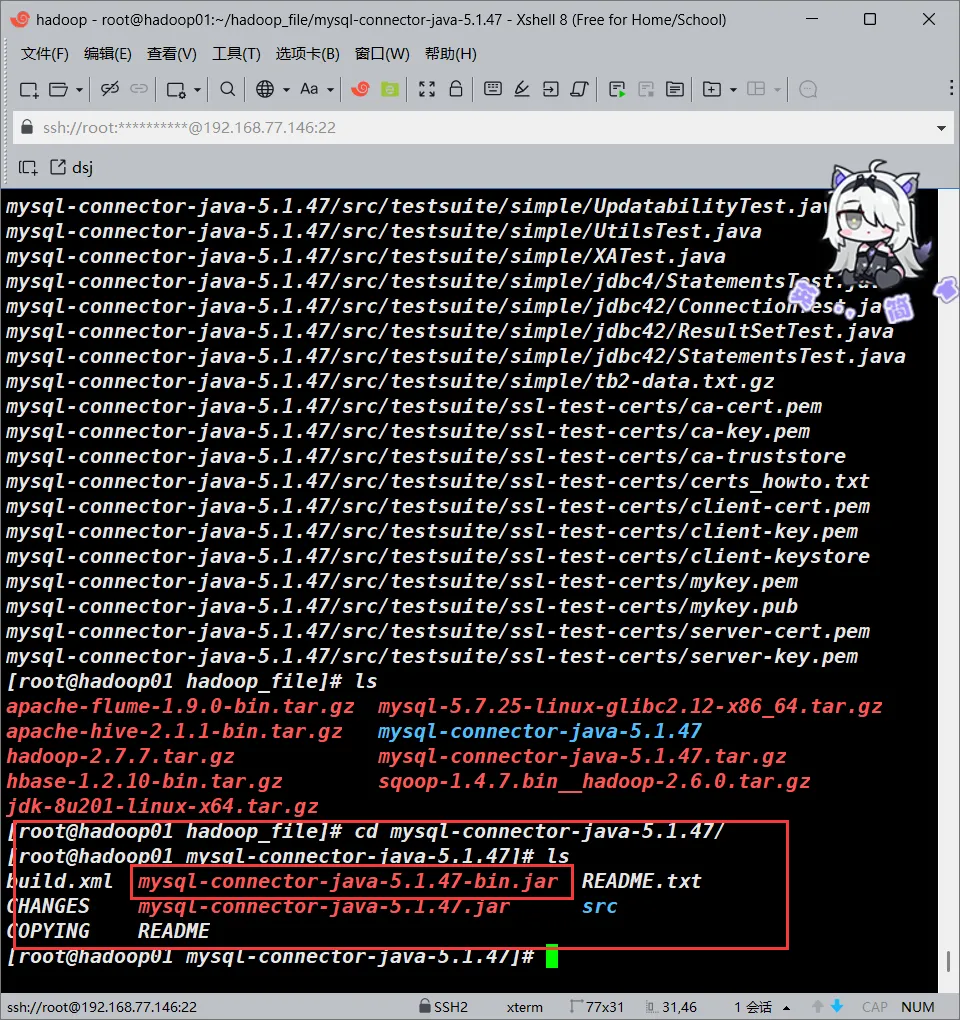
复制驱动包到sqoop-1.4.7.bin__hadoop-2.6.0/lib/下面即可
cp /root/hadoop_file/mysql-connector-java-5.1.47/mysql-connector-java-5.1.47-bin.jar /usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/lib/部署MySQL
事前准备
此处的部署我们采用直接使用编译好了的mysql包来进行部署
创建mysql文件夹并将我们的准备好的tar包解压到指定位置
mkdir /usr/mysql && tar -zxvf /root/hadoop_file/mysql-5.7.25-linux-glibc2.12-x86_64.tar.gz -C /usr/mysql创建MySQL链接
ln -s /usr/mysql/mysql-5.7.25-linux-glibc2.12-x86_64 /usr/local/mysql创建用于存放MySQL数据库数据的文件夹
mkdir /usr/local/mysql/data && chmod 770 /usr/local/mysql/data 更改链接的MySQL文件夹的所属用户和所属组
cd /usr/local/mysql
chown -R mysql .
chgrp -R mysql .配置MySQL的环境变量
配置环境变量
vim /etc/profile
#添加以下内容
MYSQL_HOME=/usr/local/mysql
PATH=$MYSQL_HOME/bin:$PATH
export MYSQL_HOME PATH
#完成之后保存退出
#从新加载环境变量
source /etc/profile初始化MySQL
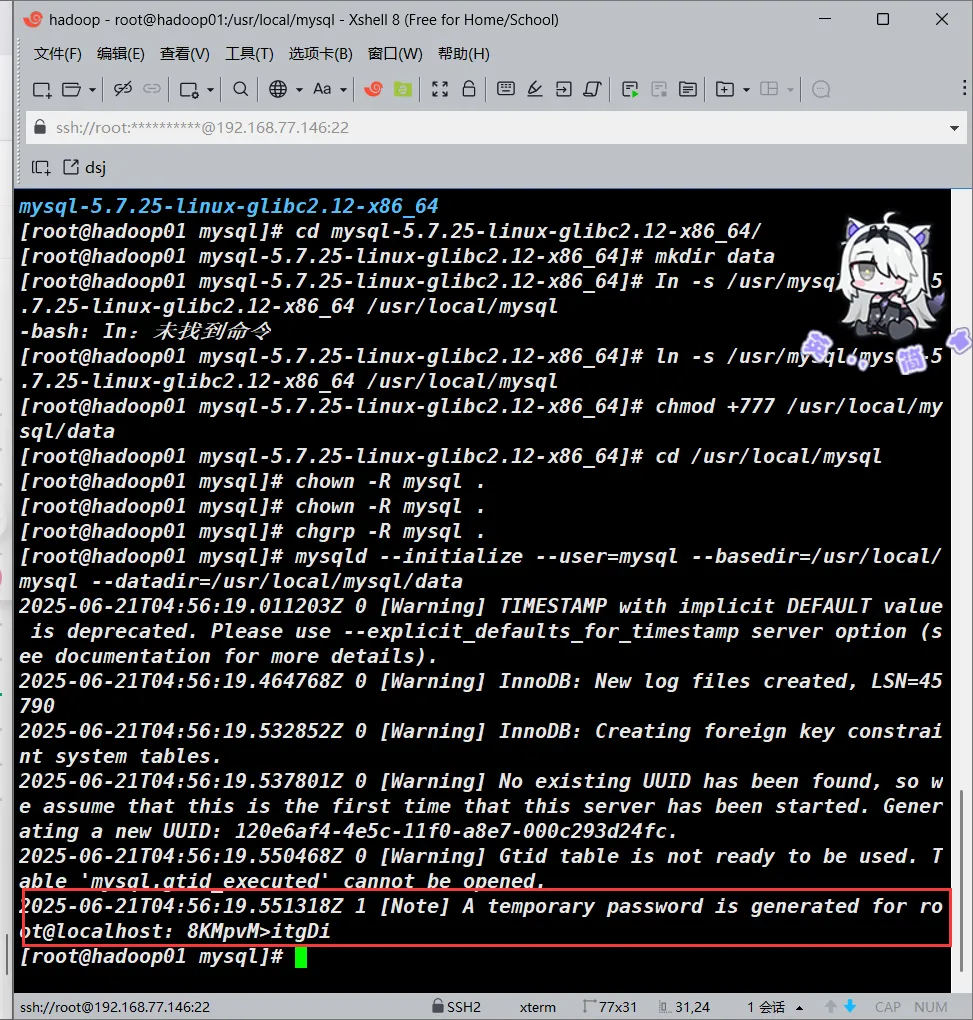
mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data正常执行的话会有以下输出
2025-06-20T15:54:01.649446Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
2025-06-20T15:54:02.012314Z 0 [Warning] InnoDB: New log files created, LSN=45790
2025-06-20T15:54:02.094503Z 0 [Warning] InnoDB: Creating foreign key constraint system tables.
2025-06-20T15:54:02.100128Z 0 [Warning] No existing UUID has been found, so we assume that this is the first time that this server has been started. Generating a new UUID: c929cff7-4dee-11f0-8ea0-000c293d24fc.
2025-06-20T15:54:02.101207Z 0 [Warning] Gtid table is not ready to be used. Table 'mysql.gtid_executed' cannot be opened.
2025-06-20T15:54:02.102200Z 1 [Note] A temporary password is generated for root@localhost: 8KMpvM>itgDi此时要注意,最后一段有一个临时密码,很重要,这个是msyql初始化后生成的一个临时的root账号的密码,我们后面要用这个密码登录mysql,然后将其改为我们自己设置的mysql密码
安装MySQL
mysql_ssl_rsa_setup --basedir=/usr/local/mysql datadir=/usr/local/mysql/data启动和验证MySQL
mysqld_safe --user=mysql --basedir =/usr/local/mysql --datadir=/usr/local/mysql/data &验证一下
ps -ef | grep mysql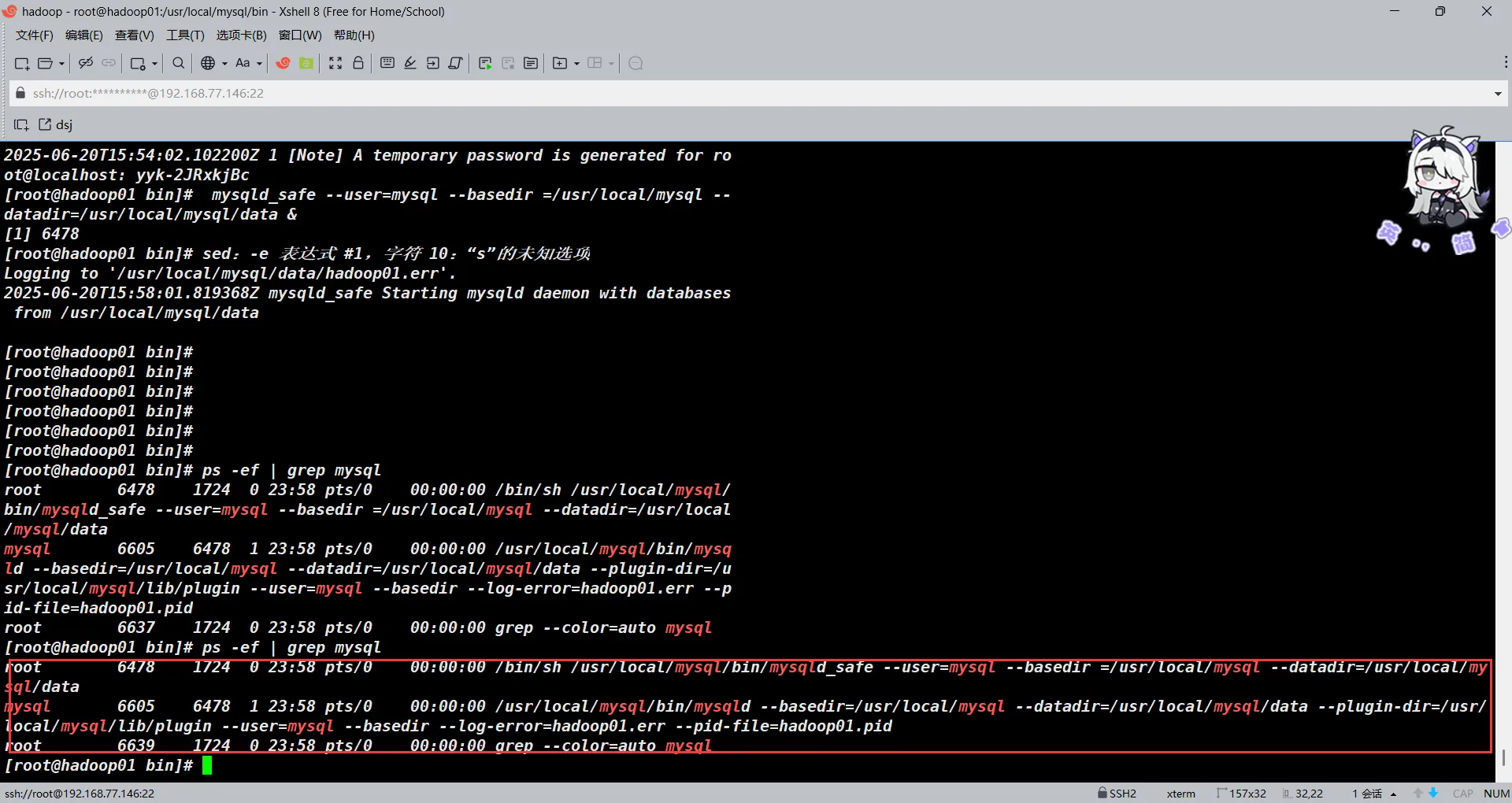
登录mysql修改密码
mysql -u root -p
#输入你刚刚获得的临时密码即可
#更改root密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'ROOT_PASSWD';请把ROOT_PASSWD换成你的MySQL的root密码
一些小问题
由于CentOS Stream 9相对于CentSO 7有了很大的改进与更新,很大一部分so.5版本的库都不再支持就例如libncurses.so.5和libtinfo.so.5
你如果也是CentOS9的话很大概率第一次登陆MySQL会出现以下报错
#主机上缺少libncurses.so.5
mysql: error while loading shared libraries: libncurses.so.5: cannot open shared object file: No such file or directory
#修复上述那个报错后会出现主机上缺少libtinfo.so.5
mysql: error while loading shared libraries: libtinfo.so.5: cannot open shared object file: No such file or directory
通过查找这两个组件你会发现


当前机器上只有so.6版本的
你就不用想着去把这个so.5的版本找过来了,太麻烦了。我印象里这些库都是向下兼容的(也许,出了问题别找我就行)我们直接一个软链接过去凑合着用一下
ln -s /lib64/libncurses.so.6 /lib64/libncurses.so.5
ln -s /lib64/libtinfo.so.6 /lib64/libtinfo.so.5之后就没问题了
配置MySQL服务
在 CentOS 9 上,传统的SysVinit(/etc/init.d/)已经被systemd取代,所以直接复制mysql.server到/etc/init.d/可能不会生效。
#虽然 systemd 是推荐方式,但如果某些脚本依赖 /etc/init.d/mysql,你可以:
# 创建 init.d 目录(CentOS9默认没有)
mkdir -p /etc/init.d
# 复制 mysql.server
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
# 赋予执行权限
chmod +x /etc/init.d/mysql
# 尝试启动(我不保证兼容性)
service mysql start Flume的部署
事前准备
创建flume并解压flume到指定文件夹
mkdir /usr/local/flume && tar -zxvf /root/hadoop_file/apache-flume-1.9.0-bin.tar.gz -C /usr/local/flume配置flume
复制模板文件成为新的配置文件
#复制文件
cp /usr/local/flume/apache-flume-1.9.0-bin/conf/flume-env.sh.template /usr/local/flume/apache-flume-1.9.0-bin/conf/flume-env.sh
#复制文件
cp /usr/local/flume/apache-flume-1.9.0-bin/conf/flume-conf.properties.template /usr/local/flume/apache-flume-1.9.0-bin/conf/flume-conf.propertiesflume-env.sh
编辑并添加以下内容
vim /usr/local/flume/apache-flume-1.9.0-bin/conf/flume-env.sh
#添加以下内容
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_201
#完成过后保存退出配置环境变量
vim /etc/profile
#添加以下内容
FLUME_HOME=/usr/local/flume/apache-flume-1.9.0-bin
PATH=$PATH:$FLUME_HOME/bin
export FLUME_HOME PATH
#完成后保存退出
#之后别忘了重新加载环境变量
source /etc/profileHive的部署
事前准备
创建Hive文件夹并解压Hive到指定位置
mkdir /usr/local/hive && tar -zxvf /root/hadoop_file/apache-hive-2.1.1-bin.tar.gz -C /usr/local/hive/配置Hive
环境变量
我们首先先来更改一下环境变量
vim /etc/profile
#添加以下内容
HIVE_HOME=/usr/local/hive/apache-hive-2.1.1-bin/
export PATH=$PATH:$HIVE_HOME/bin
export HIVE_HOME PATH
#完成后保存退出
#之后别忘了重新加载环境变量
source /etc/profile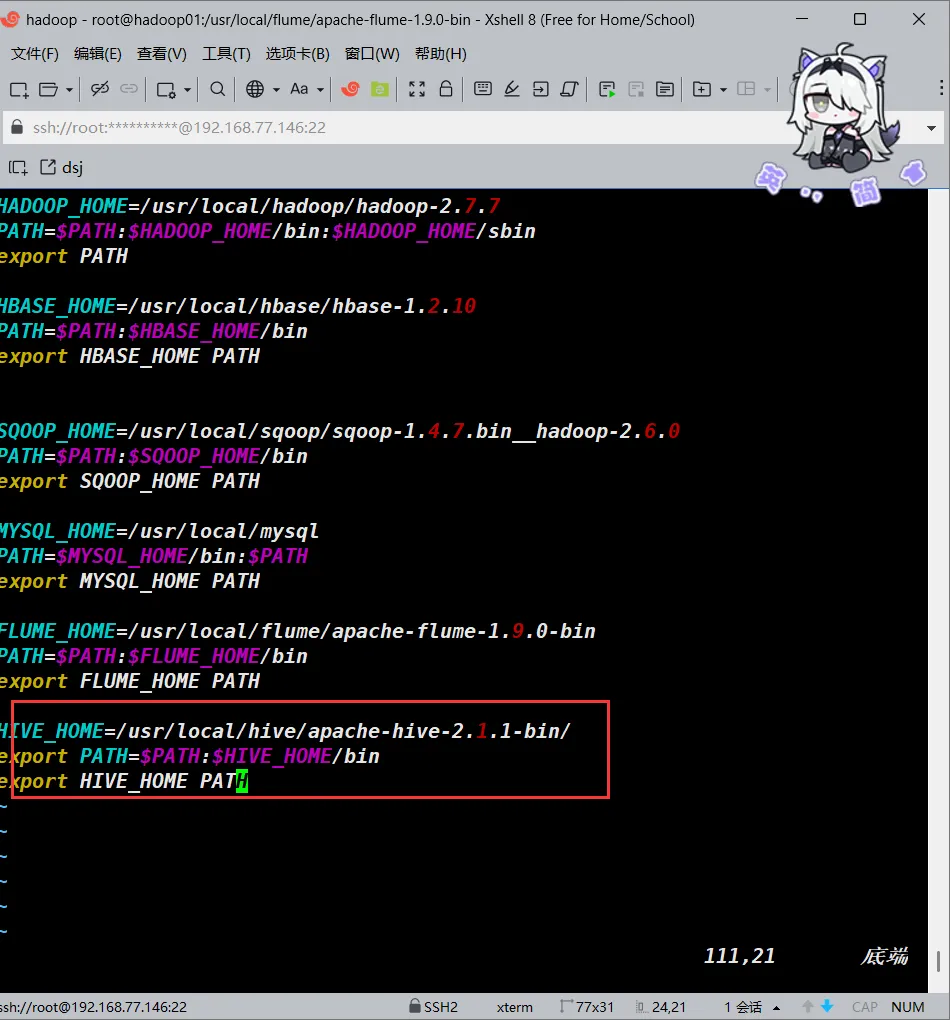
hive-site.xml
#hive-site.sh的源文件是hive-default.xml.template
#我们要先吧这个复制一份出来
cp /usr/local/hive/apache-hive-2.1.1-bin/conf/hive-default.xml.template /usr/local/hive/apache-hive-2.1.1-bin/conf/hive-d.xml 配置hive-site.xml
此文件要配置的地方比较多
javax.jdo.option.ConnectionURL
首先是文件内的javax.jdo.option.ConnectionURL项
我们可以直接在vim里面搜索该选项,大概位置在501行
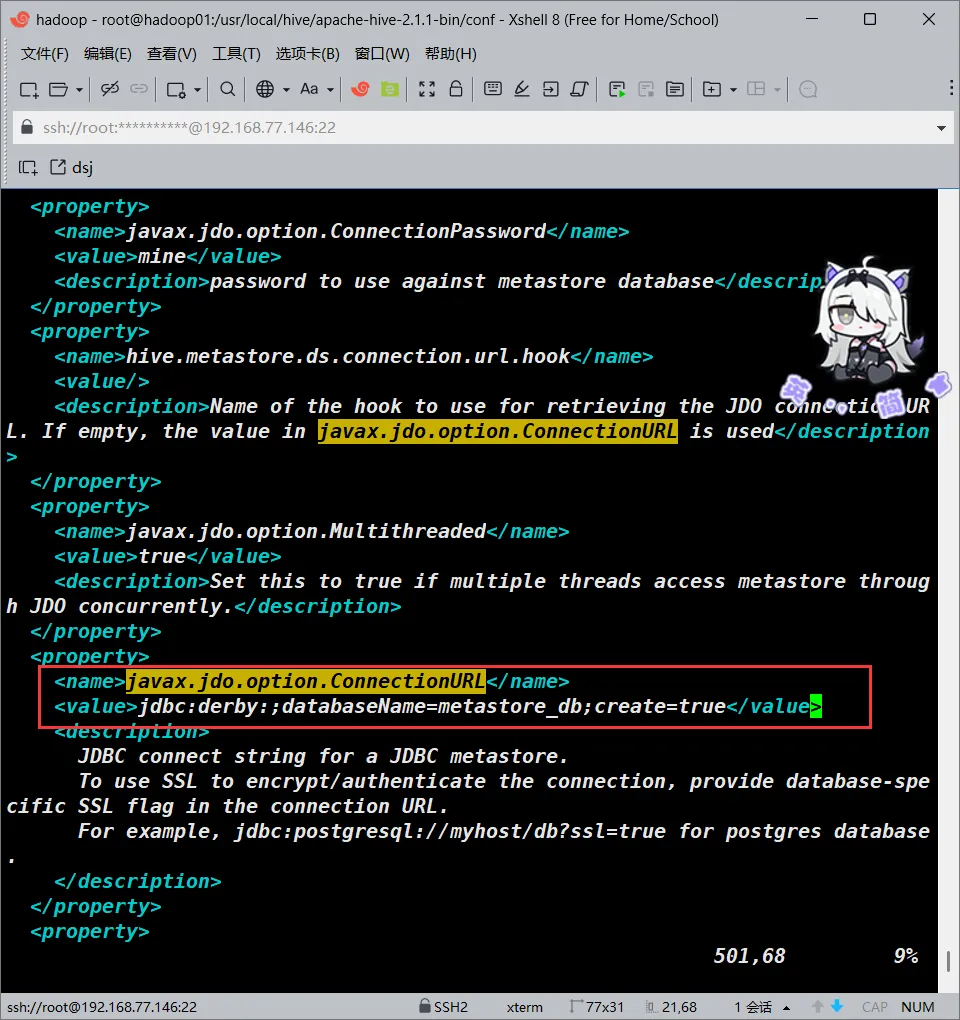
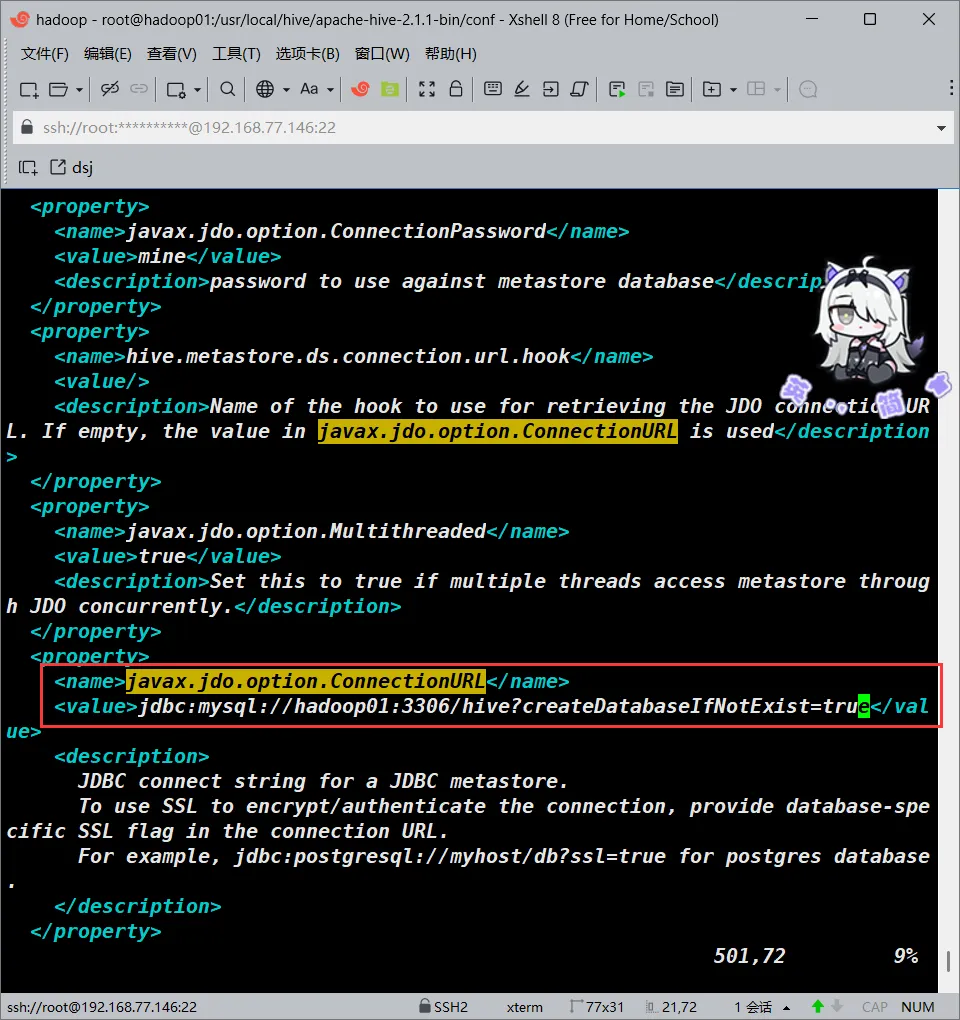
我们将该字段的value改成如下内容
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>javax.jdo.option.ConnectionDriverName
将javax.jdo.option.ConnectionDriverName处配置的value改成如下配置
大概在932行
<value>com.mysql.jdbc.Driver</value>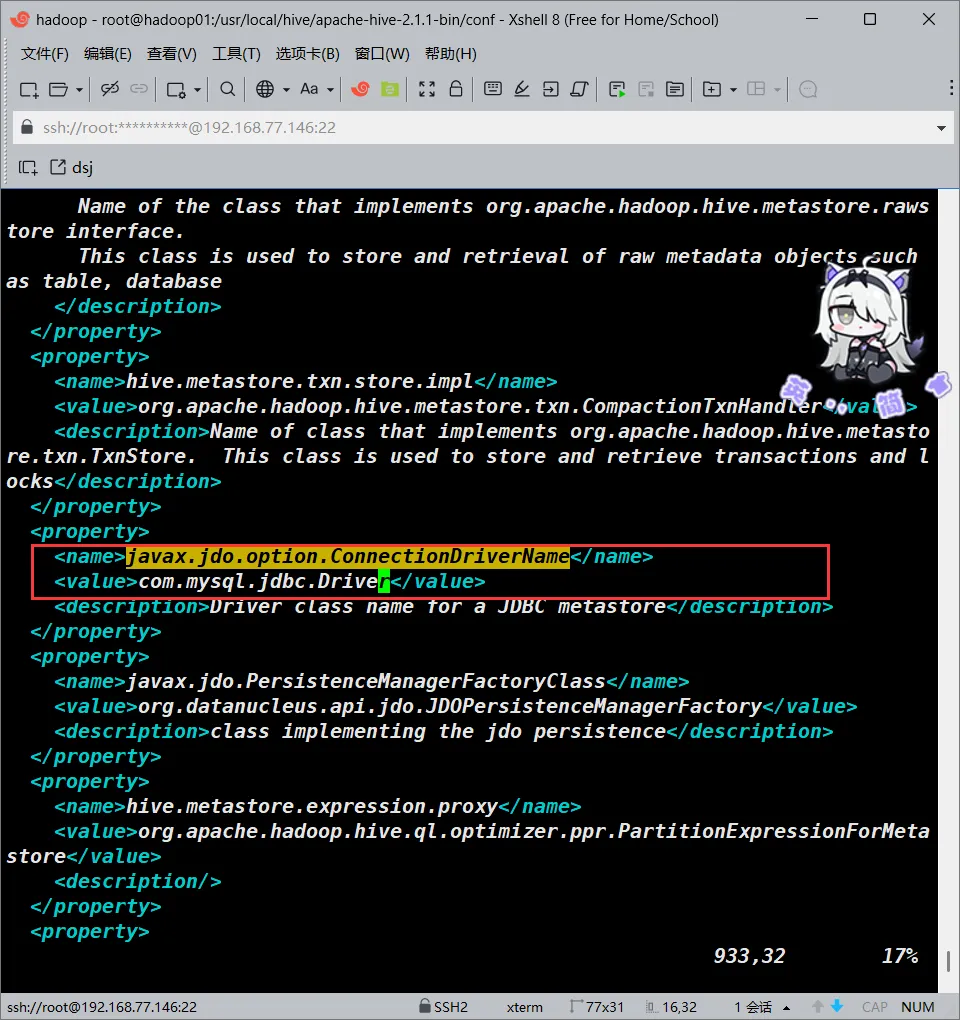
javax.jdo.option.ConnectionUserName
这个大概在957行
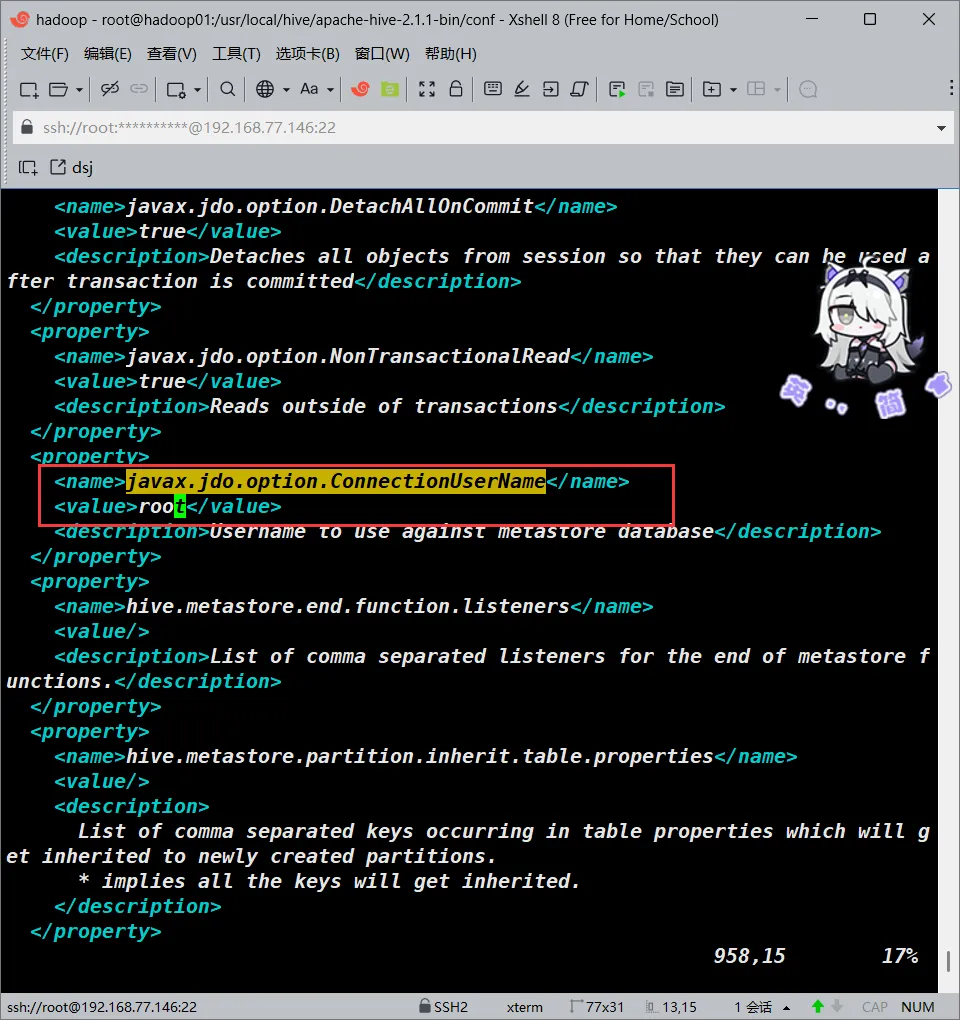
<!--->将<value>的值改为<--->
<value>root</value>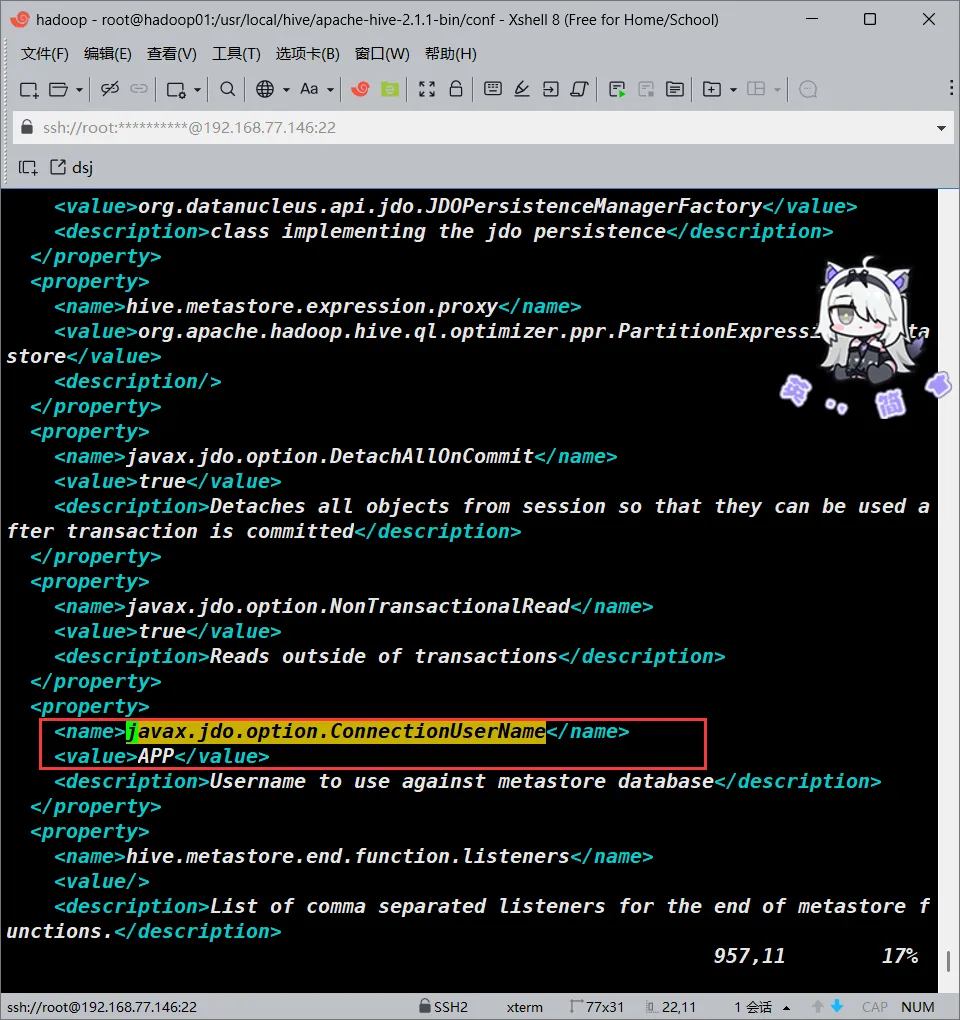
javax.jdo.option.ConnectionPassword
大概在485行
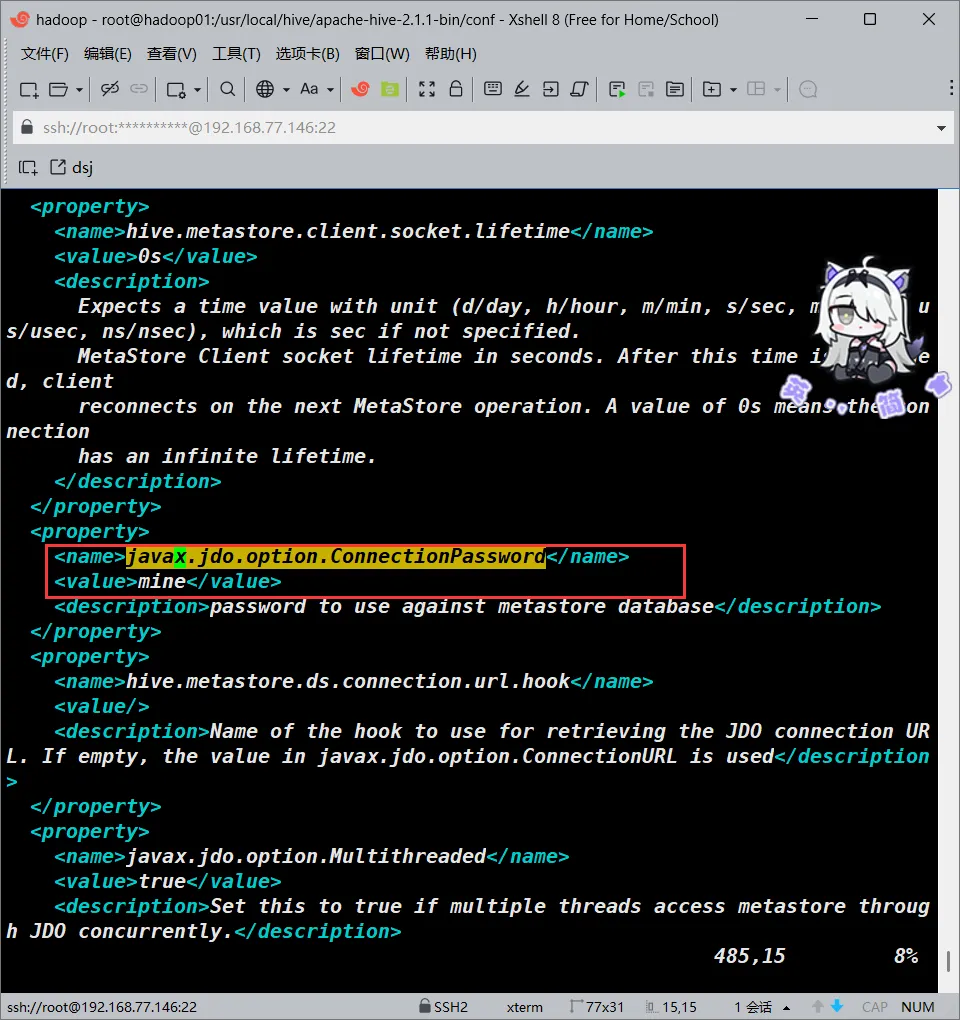
<!--->更改<value>的值为你的数据库的root密码<--->
<value>YOUR_SQL_PASSWD</value>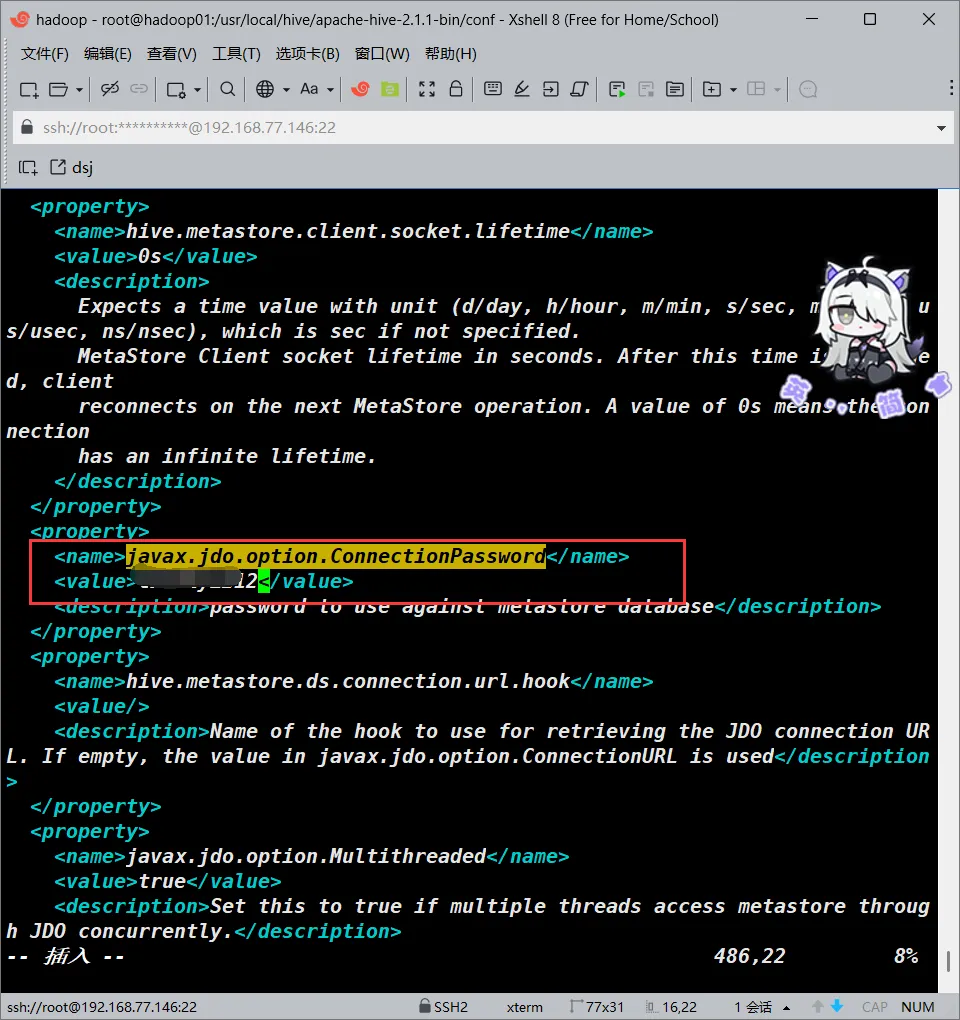
hive.metastore.schema.verification
大概在686行
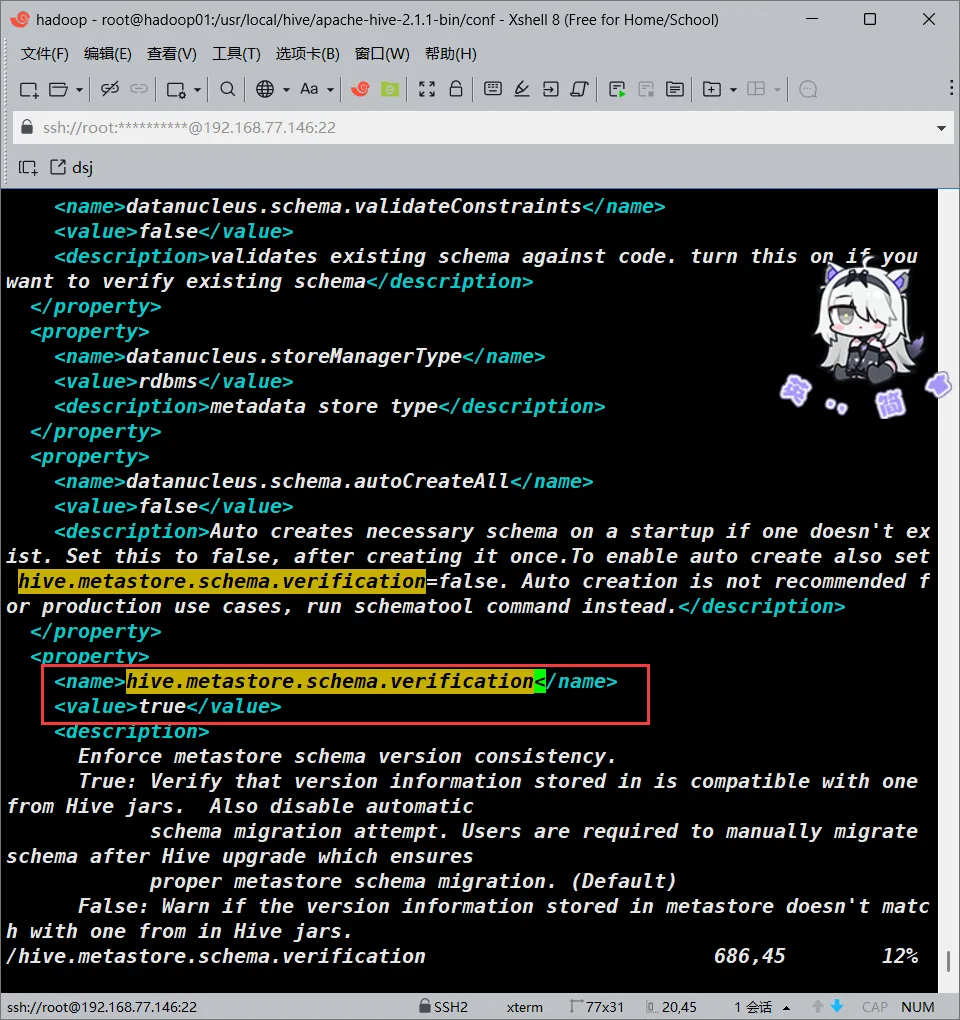
<!--->更改<value>的值为false<--->
<value>false</value>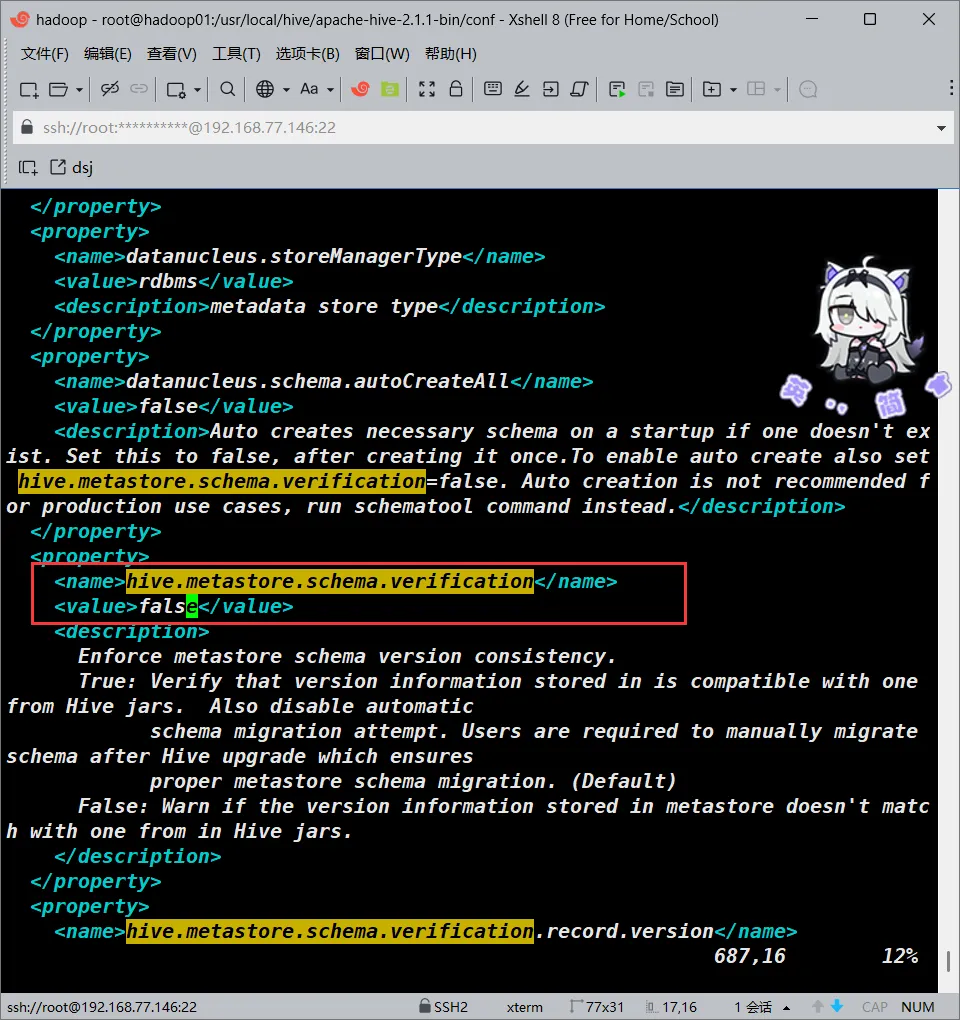
system:java.io.tmpdir
对于这个字段,我们要将其全部替换成/usr/hive/apache-hive-2.1.1-bin/tmp
system:user.name
对于这个字段,我们将其全部替换成user.name
驱动准备
还是mysql-connector-java-5.1.47-bin.jar
我们要将其放到/usr/local/hive/apache-hive-2.1.1-bin/lib下
cp /root/hadoop_file/mysql-connector-java-5.1.47/mysql-connector-java-5.1.47-bin.jar /usr/local/hive/apache-hive-2.1.1-bin/lib/ 初始化元数据库
之后我们初始化元数据库
schematool -initSchema -dbType mysql
#等待出现schemaTool completed即可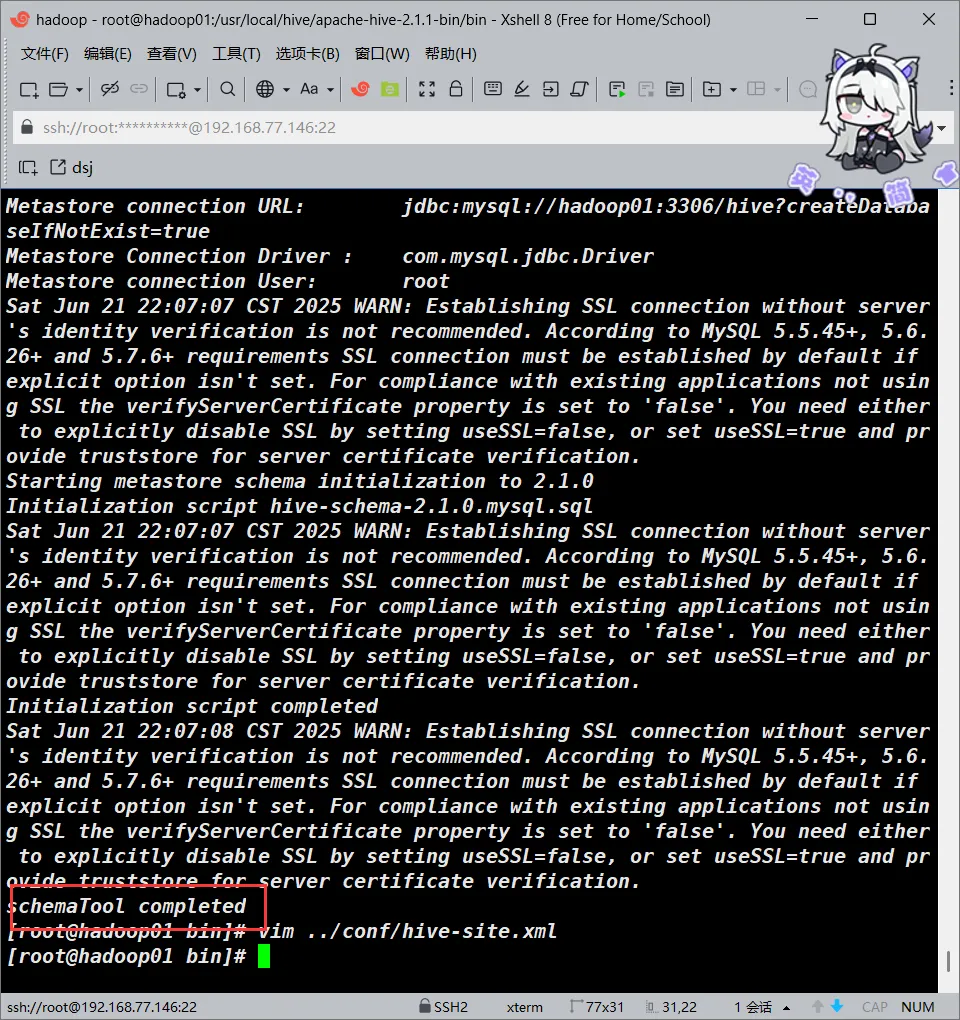
如果出现了这种错误
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/apache-hive-2.1.1-bin/lib/lo
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.7.7/share/hadoop/
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanatio
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://hadoop01:3306/hive?createDatabas
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema versi
Underlying cause: java.sql.SQLException : null, message from server: "Unknown
SQL Error code: 1130
Use --verbose for detailed stacktrace.
*** schemaTool failed ***这一般意味着你的mysql没有允许远程访问开启即可
至此,hive基本已经安装完毕
评论(0)
暂无评论